Прамотроник 15.8106-05 автономный подогреватель МАЗ КАМАЗ
ПЖД Прамотроник 15.8106-05
Посмотреть ЦЕНУАвтономный подогреватель двигателя для а/м МАЗ, КАМАЗ, КрАЗ, УРАЛ, АМО ЗИЛ
Принцип работы автономного подогревателя Прамотроник 15.8106-05 аналогичен модели Прамотроник 15.8106-15. Эта модификация разработана только для ряда автомобилей отечественного производства — МАЗ, КАМАЗ, КрАЗ, УРАЛ, АМО ЗИЛ. В штатной проводке этих автомобилей уже есть все необходимые жгуты и кабели для подключения подогревателя, что существенно упрощает его монтаж. Однако при необходимости подключить подогреватель двигателя Прамотроник 15.8106-05 можно к любой технике, но для этого потребуются кабели, наличие которых не предусмотрено в заводской комплектации.
Включение и выключение подогревателя 15.8106-05 может осуществляется при помощи любого переключателя (кнопки). Для расширения возможностей управления можно использовать электронный пульт (*опция), который устанавливается в кабине автомобиля и позволяет программировать время запуска подогревателя в автоматическом режиме.
Область применения Прамотроник 15.8106-05:
- Автофургоны
- Небольшие автобусы
- Грузовые автомобили
- Спецтехника
Технические характеристики подогревателя двигателя
| Прамотроник 15.8106-05 | |
| Теплопроизводительность, кВт | 15 |
| Расход топлива, л/час | 1,2 |
| Потребляемая мощность отопителя, Вт | 93,5 |
| Применяемое топливо | Дизельное топливо |
| Номинальное напряжение питания, В | 24 |
* жгуты, пульт управления, помпа, выхлопная труба, топливопровод, шланги и крепёж в комплект не входят.

Отзывы владельцев МАЗ 6501
Отзывы владельцев МАЗ 6501
МАЗ 6501, 2005 г
Первый МАЗ был у меня 10-тонник. Отработал со мной 5 лет. В целом, без особых проблем. Потому что он был рассчитан именно на пять лет. Учитывая мой опыт, он был быстренько продан. Назревали проблемы с КПП и задним мостом. Да и рама оказалась слабой на скручивание. Появились трещины. Очень неустойчив при выгрузке. Пока выгрузишься на насыпном грунте, весь мокрый. Потом пять лет был КамАЗ. Та ещё птица. И вот, наконец, купил МАЗ 6501 самосвал (на китайца не хватило). Первое впечатление – удивлен. 4-точечная кабина, климат-контроль (русский, правда), сиденье пневматическое, торпеда новая и т.д. Но это только первое впечатление, а потом понеслось: балансир течет ручьём с обеих сторон, штуцер гидроцилиндра подъёма кузова тоже. Всё, что сделано в Белоруссии, пришлось протягивать. К двигателю и КПП это не относится — пока. И самая главная проблема МАЗ 6501 на сегодня — как загрузишь самосвал, так он передним бампером ползет по земле (не перегруз).
Достоинства: на МАЗе стараются улучшить машину. Много современного, нового.
Недостатки: нужно дать по рукам тому, кто собирал мою машину.
Валерий, Венёв
МАЗ 6501, 2013 г
Ну вот я и стал счастливым обладателем нового МАЗ 6501. Взял с двигателем ЯМЗ536 310 сил. Рядная шестёрка. Сказали, что я третий обладатель машины с таким двигателем в России. Недавно заехал на первое плановое ТО после обкатки. Пробег уже 2400. В заводской книге по двигателю рекомендовано масло Шелл и льется всего 23 литра в ДВС. В коробку и мосты было решено залить Мобил. Тихо заехав на СТО, сбежались все мастера и механики и сразу полезли смотреть двигатель.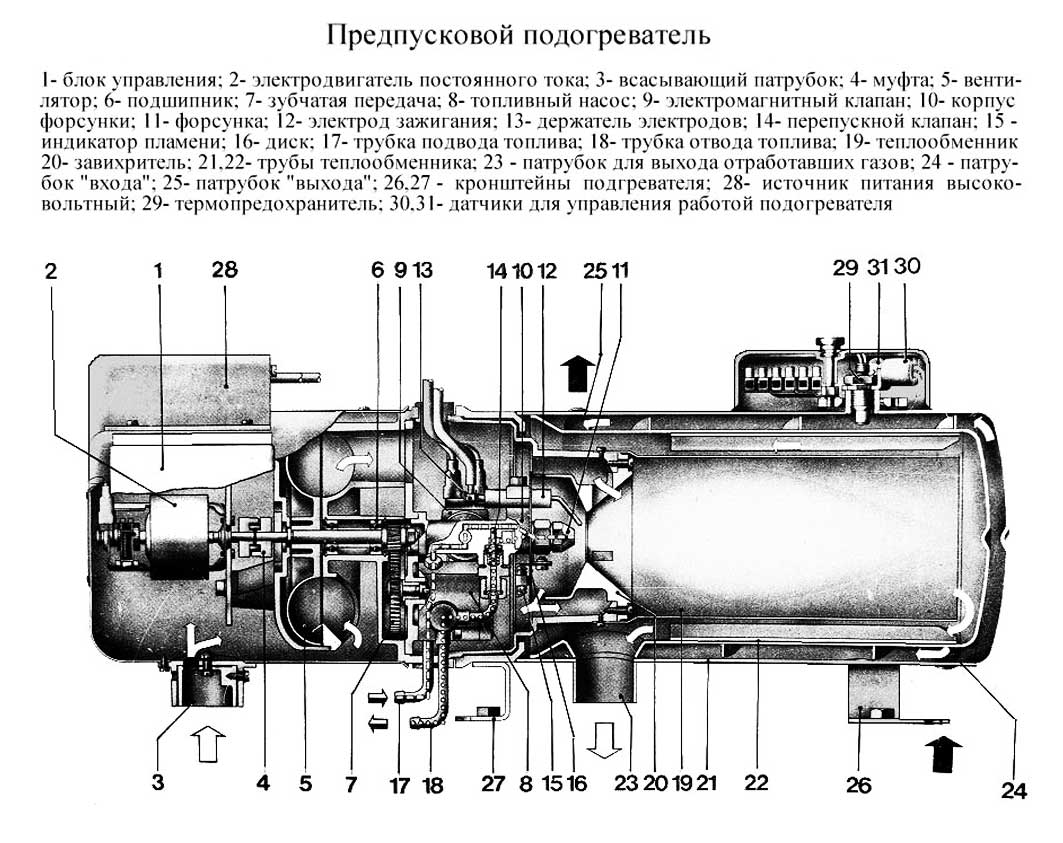 Из косяков по машине: не работает обдув лобового стекла. В сильный мороз не запускается «автономка» двигателя, хотя и стоит немецкая (видимо, что русскому хорошо — немцу смерть). Также не работает указатель температуры охлаждающей жидкости и уровня топлива. А ведь новая машина. Пока гнал, засёк расход — по трассе 33-34 литра. По истечении двух дней была настроена вязкостная муфта и оптимизирована работа двигателя. Машина стала экономичнее. Но расход всё-равно не радует, говорят, что после 10 тыс. пробега упадёт. Качеством обслуживания МАЗ 6501 в целом я недоволен. Самосвалы в МАЗ вообще не умеют и не хотят делать. Расход со временем действительно упал. Сейчас пробег составляет 10 тыс. км. Течь из бака цилиндра и течь антифриза — это нормальное явление, которое не собираются исправлять сказали мне на сервисе. Ещё скажу всем, кто собирается покупать отечественную технику. Продайте всю резину сразу, пока новая и, добавив немного денег, купите «китайку» и вы забудете о проблемах с перегрузами.
Из косяков по машине: не работает обдув лобового стекла. В сильный мороз не запускается «автономка» двигателя, хотя и стоит немецкая (видимо, что русскому хорошо — немцу смерть). Также не работает указатель температуры охлаждающей жидкости и уровня топлива. А ведь новая машина. Пока гнал, засёк расход — по трассе 33-34 литра. По истечении двух дней была настроена вязкостная муфта и оптимизирована работа двигателя. Машина стала экономичнее. Но расход всё-равно не радует, говорят, что после 10 тыс. пробега упадёт. Качеством обслуживания МАЗ 6501 в целом я недоволен. Самосвалы в МАЗ вообще не умеют и не хотят делать. Расход со временем действительно упал. Сейчас пробег составляет 10 тыс. км. Течь из бака цилиндра и течь антифриза — это нормальное явление, которое не собираются исправлять сказали мне на сервисе. Ещё скажу всем, кто собирается покупать отечественную технику. Продайте всю резину сразу, пока новая и, добавив немного денег, купите «китайку» и вы забудете о проблемах с перегрузами.
Достоинства: неплохой двигатель. Удобная кабина.
Недостатки: много мелких недоработок. Качество.
Антон, Москва
МАЗ 6501, 2013 г
По мягкости хода против 20-тонника «татарина» МАЗ 6501 однозначно мягче. А с новой кабиной приятнее вдвойне. Я про четырёхосный. У меня кузов длинный, а у новых короткий. У меня электроннотроссовая педаль газа, а новые полностью с «мозгами». Коробка и сцепление на МАЗ 6501 — болезнь хроническая. Очень не хватает половинки в коробке. 4 много, а 5 мало. Качество сборки нулевое. «Батьку» надо на завод отправить, чтоб криворуких вылечил. После проблем с МАЗ 6501 «дубовую» Ивеко ласково вспоминаю. Будет возможность — пересяду не думая на иномарку.
Достоинства: комфортнее КамАЗа.
Недостатки: коробка и сцепление.
Сергей, Москва
Блок управления свечами накаливания — подробная информация
Каковы признаки неисправности блока управления свечами накаливания?
В дизельном двигателе установлен один блок управления свечами накаливания. Это означает, что вы можете не заметить выход из строя одной свечи накаливания, поскольку она влияет только на один из цилиндров двигателя. Однако если в негодность приходят две или три свечи или блок управления целиком, вы вскоре столкнетесь с трудностями при запуске двигателя. Следите, не загорается ли сигнализатор неисправности свечи накаливания на панели приборов. Помимо этого есть несколько распространенных признаков неисправности свечи накаливания или блока управления:
Это означает, что вы можете не заметить выход из строя одной свечи накаливания, поскольку она влияет только на один из цилиндров двигателя. Однако если в негодность приходят две или три свечи или блок управления целиком, вы вскоре столкнетесь с трудностями при запуске двигателя. Следите, не загорается ли сигнализатор неисправности свечи накаливания на панели приборов. Помимо этого есть несколько распространенных признаков неисправности свечи накаливания или блока управления:
- Белый дым из выхлопной трубы — неисправность свечи накаливания вызывает протечку дизельного топлива в выхлопную систему, где оно сгорает.
- Сложности с запуском двигателя — это означает, что двигатель плохо запускается в теплую погоду и не запускается вовсе в холодную погоду. Однако это может быть также признаком неисправности топливной системой или аккумуляторной батареи.
- Недостаточная мощность двигателя — после сложного запуска неисправные свечи накаливания затрудняют работу двигателя из-за неправильного сгорания, что снижает мощность двигателя и его эффективность.


Как можно проверить блок управления свечами накаливания?
Первым делом определите, это проблема в свечах накаливания или в блоке управления свечами накаливания?
Проще всего сначала проверить свечи накаливания, а затем блок управления.
Для проверки свечей накаливания просто подсоедините лампу-тестер 12 В к положительной клемме аккумуляторной батареи. Затем отсоединяйте провода от каждой свечи накаливания и прикасайтесь щупом лампы-тестера к клемме самой свечи (не к проводам). Если лампа не загорается, свеча накаливания неисправна и ее необходимо заменить.
Проще всего воспользоваться профессиональным тестером свечей накаливания.
Есть разные мнения касательно того, заменять ли только неисправные свечи накаливания или все сразу. Поскольку неисправность одной свечи может быть признаком того, что вскоре за ней последуют и остальные, некоторые специалисты рекомендует заменить все свечи сразу. Другие же предлагают пристально следить за оставшимися свечами накаливания.
Если свечи накаливания исправны, переходите к блоку управления. Начните с проверки напряжения на блок управления свечами накаливания. Уменьшение напряжения на половину вольта (или больше) означает, что блок управления необходимо заменить.
Как выбрать подходящий блок управления свечами накаливания?
Поскольку свечи накаливания и блоки управления свечами накаливания не универсальны, важно выбрать подходящие для вашего автомобиля и топлива. Кроме того, рекомендуется использовать компоненты наилучшего качества, поскольку детали низкого качества могут стать причиной последующего дорогостоящего ремонта. Например, вздутую свечу накаливания, изготовленную из низкокачественных материалов, может быть невозможно потом демонтировать или ее кончик может отломиться внутри цилиндра и повредить цилиндр, клапан и головку.
Автономность | Мегами Тенсей Вики
Тесно – стены смыкаются вокруг меня
Как жестокий сон
Белое, серое, черное и каштановое
Лабиринт крутых поворотов
Небо – я вижу часть его, смотрящую прямо вверх
Got подняться вверх
Ярко-голубой квадрат солнца
Кусочек хорошей жизни
Так далеко
Кто сказал, что я не могу дотянуться до этого квадрата неба
Что я не могу подняться вверх
В небо
Поднимись высоко
Автономия
Почти в пределах моей досягаемости
Поднимись высоко
Возьми мое небо
Моя истинная целостность
Разрушь лабиринт игры, которую мы
Играй – я ничего не могу сделать, кроме как играть сейчас
Играй – и побеждай, единственный выход
Сюжет должен разыгрываться
До конца
Игры – общество всегда меняется
Правила и нормы соперники и друзья?
Моря – иногда я вижу их вдалеке
Я слушаю
Пожалуйста – кто-нибудь там слышит меня
Моя надежда на свободное плавание
За пределами игры?
Сердце в тисках, но я каким-то образом вырвался Я проснулся и нашел (я могу)
Еще один крутой поворот
По пути
Я знаю, что смогу найти дорогу к ветру
И к открытым водам
Ставлю паруса
Я не могу потерпеть неудачу
Автономия
Теперь почти в пределах досягаемости
Брось вызов морям
Найди мой покой
Мне нужно только пробиться
Эти старые стены, сломай их всех
Удары – градом сыплются на мою голову сейчас
Должен залог сейчас
Выбрал победу, мое единственное правило
Мой единственный ход
Остаться на вершине
Завесы – которые скрывают программу, запускающую прорыв лабиринта
Под моим взглядом
Сказки растут, когда я иду быстрее
На встречу с моим хозяином
И я не остановлюсь
Кто-нибудь я не верю, что могу победить?
Рядом со мной,
Кто действительно на моей стороне?
Только я сам и я, эта команда
Становится сильным и диким
Со временем
Поднимись высоко
Чувствую себя диким
Автономия
Сейчас почти в пределах досягаемости
Небо и море
Освободи меня
Автономия
Я буду храбрым
Любая волна
Автономия
Теперь почти в пределах досягаемости
Небо и море
Освободи меня
Мне нужно только пробиться все вниз
Любовь – жить, моя единственная цель – выжить
Должен остаться в живых
Что ты собираешься сделать, чтобы остановить меня?
Никто не может остановить меня
Я в ударе Держись подальше от моего пути
Я уже в пути
Полет близок, поскольку я иду на гонку
Потому что я преследую
Автономность сейчас
границ | Баланс производительности и автономии человека с агентом неявного руководства
1 Введение
Когда люди работают в сотрудничестве с другими, они могут выполнять то, что было бы трудно сделать в одиночку, и часто достигают своих целей более эффективно. С недавним развитием технологий искусственного интеллекта все более важной темой становится взаимодействие человека и агента, в котором люди и агенты ИИ работают вместе. Роль агентов в этой проблеме заключается в сотрудничестве с людьми для достижения поставленной задачи.
С недавним развитием технологий искусственного интеллекта все более важной темой становится взаимодействие человека и агента, в котором люди и агенты ИИ работают вместе. Роль агентов в этой проблеме заключается в сотрудничестве с людьми для достижения поставленной задачи.
Одним из типов интуитивного агента для совместной работы является вспомогательный агент , который помогает человеку, предсказывая цель человека и планируя действие, которое лучше всего поможет ее достижению. В последние годы появились агенты, которые могут эффективно планировать, определяя человеческие подцели для разделенной задачи на основе байесовской теории разума (Wu et al., 2021). Другие агенты проявляют предвзятое поведение для общего сотрудничества, например, сообщая или скрывая свои намерения (Strouse et al., 2018), максимизируя управляемость человека (Du et al., 2020) и так далее. Однако на самом деле эти агенты не могут изменить план человека, а это означает, что окончательный успех или провал совместной задачи зависит от способности человека планировать. Другими словами, если человек установит неправильный план, производительность пострадает.
Другими словами, если человек установит неправильный план, производительность пострадает.
Как правило, люди не могут планировать оптимальные действия для решения сложных задач из-за ограниченности своих когнитивных и вычислительных способностей.На рис. 1 показан пример вводящей в заблуждение командной задачи «человек-агент» как одной из таких сложных проблем. Задача представляет собой разновидность задачи преследования-уклонения. Человек и агент стремятся захватить одного из персонажей (показанного в виде лица), сотрудничая вместе и приближаясь к персонажу с обеих сторон. На рисунке 1А есть два символа, 1) и (2), на верхней и нижней дорогах соответственно. Поскольку 1) находится дальше, 2) кажется более подходящей целью. Однако 2) не может быть захвачен, потому что он может уйти через нижний обходной путь.С другой стороны, на рисунке 1B агент и человек могут успешно захватить 2), потому что он находится немного левее, чем на рисунке 1A. Таким образом, лучшая цель может измениться из-за небольшой разницы в задаче, и людям может быть трудно судить об этом.
РИСУНОК 1 . Пример сложной командной задачи человек-агент.
Один из наивных подходов к решению такой проблемы заключается в том, чтобы агент направлял действия человека к оптимальному плану. Поскольку агенты обычно не имеют когнитивных или вычислительных ограничений, им легче составить оптимальный план, чем людям.После того, как агент составит оптимальный план, он может явно направить поведение человека на достижение цели. Например, есть агент, который выполняет дополнительные действия для передачи информации другим с дополнительными затратами (Kamar et al., 2009), где он сначала решает, должен ли он помогать другим, оплачивая эту стоимость. Поскольку такое руководство явно доступно для наблюдения людьми, мы называем его явным руководством в этой статье. Однако, если агент злоупотребляет явным руководством, человек может потерять чувство контроля над принятием решений при выполнении совместной задачи, другими словами, свою автономию.В результате человек может чувствовать, что он находится под контролем агента. Например, в объединении человека и робота, если робот решает, кто будет выполнять каждую задачу, ситуационная осведомленность человека снизится. (Гомболей и др., 2017).
Например, в объединении человека и робота, если робот решает, кто будет выполнять каждую задачу, ситуационная осведомленность человека снизится. (Гомболей и др., 2017).
Чтобы уменьшить этот риск, агенты должны направлять людей, позволяя им сохранять автономию. Мы фокусируемся на неявном руководстве, предлагаемом через поведение. Неявное руководство основано на когнитивном знании о том, что люди могут делать выводы о намерениях других на основе их поведения (Baker et al., 2009) (Бейкер и др., 2017). Агент будет ожидать, что человек сделает вывод о его намерениях и откажется от любых планов, которые не соответствуют тому, что, по их мнению, планирует агент. В соответствии с этим ожиданием агент действует таким образом, чтобы человеку было легко найти наилучший (или, по крайней мере, лучший) план для оптимального выполнения совместной задачи. Неявное руководство такого рода должно помочь людям сохранить автономию, поскольку отказ от планов является упреждающим действием человека.
Рисунок 2A является примером подробного руководства по проблеме на рисунке 1.Агент напрямую направляет человека к лучшей цели и ожидает, что человек последует за ним. Рисунок 2B является примером неявного руководства. Когда агент движется вверх, человек может сделать вывод, что агент стремится к верхней цели, наблюдая за движением агента. Хотя технически это то же самое, что и агент, явно показывающий целевой персонаж, мы чувствуем, что в этом случае люди будут чувствовать себя так, как будто они могут поддерживать автономию, добровольно делая вывод о цели агента.
РИСУНОК 2 .Пример агента с руководством.
В этой работе мы исследуем преимущества неявного руководства. Во-первых, мы моделируем три типа взаимодействующих агентов: поддерживающий агент, агент явного руководства и агент неявного руководства. Наш подход к планированию агентов основан на частично наблюдаемом марковском процессе принятия решений (POMDP), где ненаблюдаемое состояние является целью, к которой должен стремиться человек, а модель поведения человека включена в переходную среду. Наш подход прост, в отличие от более сложных подходов, таких как интерактивный POMDP (I-POMDP) (Gmytrasiewicz and Doshi, 2005), который может бесконечно моделировать двунаправленный рекурсивный вывод о намерении.Однако, поскольку есть исследования, показывающие, что у людей есть когнитивные ограничения (De Weerd et al., 2013) (de Weerd et al., 2017) в отношении рекурсивного вывода о намерениях, такая модель может быть слишком сложной для представления и недостаточно интуитивной.
Наш подход прост, в отличие от более сложных подходов, таких как интерактивный POMDP (I-POMDP) (Gmytrasiewicz and Doshi, 2005), который может бесконечно моделировать двунаправленный рекурсивный вывод о намерении.Однако, поскольку есть исследования, показывающие, что у людей есть когнитивные ограничения (De Weerd et al., 2013) (de Weerd et al., 2017) в отношении рекурсивного вывода о намерениях, такая модель может быть слишком сложной для представления и недостаточно интуитивной.
Для нашего агента неявного наведения мы добавляем к формулировке POMDP фактор, заключающийся в том, что человек делает вывод о цели агента и изменяет свою собственную цель. Эта функция основана на концепции когнитивной науки, известной как теория разума. Интеграция когнитивной модели человека в функцию перехода состояния не является чем-то необычным: это наблюдалось у напористых роботов (Taha et al., 2011) и помощниками для игр (Macindoe et al., 2012). Примеры, которые ближе к нашему подходу, включают исследование совместного планирования (Dragan, 2017) с использованием 90 121 разборчивого 90 122 действия (Dragan et al. , 2013) и другое планирование с учетом человеческого фактора (Chakraborti et al., 2018). Они похожи на нашу концепцию в том смысле, что агент ожидает, что человек сделает вывод о его намерениях или поведенческой модели. Однако эти подходы предполагают, что человек не меняет своей цели и не ориентируют цель человека на что-то более предпочтительное.Что касается более практичных моделей поведения, то были проведены исследования по интеграции модели, полученной из журнала поведения человека (Jaques et al., 2018; Carroll et al., 2019). Однако этот подход требует огромного количества журналов взаимодействия для человека, который является партнером в совместной задаче. Преимущество нашего подхода заключается в «специальном» сотрудничестве (Stone et al., 2010), т. е. в сотрудничестве без предварительной информации о противнике. Мы также принимаем байесовскую теорию разума. В области когнитивной науки в нескольких исследованиях изучалось, как люди передают другим свои знания, и для этой цели часто используется байесовский подход.
, 2013) и другое планирование с учетом человеческого фактора (Chakraborti et al., 2018). Они похожи на нашу концепцию в том смысле, что агент ожидает, что человек сделает вывод о его намерениях или поведенческой модели. Однако эти подходы предполагают, что человек не меняет своей цели и не ориентируют цель человека на что-то более предпочтительное.Что касается более практичных моделей поведения, то были проведены исследования по интеграции модели, полученной из журнала поведения человека (Jaques et al., 2018; Carroll et al., 2019). Однако этот подход требует огромного количества журналов взаимодействия для человека, который является партнером в совместной задаче. Преимущество нашего подхода заключается в «специальном» сотрудничестве (Stone et al., 2010), т. е. в сотрудничестве без предварительной информации о противнике. Мы также принимаем байесовскую теорию разума. В области когнитивной науки в нескольких исследованиях изучалось, как люди передают другим свои знания, и для этой цели часто используется байесовский подход. Например, исследователи использовали байесовский подход для моделирования того, как люди обучают понятию предмета, показывая предмет учащимся (Shafto et al., 2014). В другом исследовании байесовский подход использовался для моделирования того, как люди учат своих поведенческих предпочтений путем демонстрации (Ho et al., 2016). Обширные доказательства такого рода привели ко многим вариациям когнитивной модели человека, основанной на байесовской теории разума, например, для эгоцентричных агентов (Nakahashi and Yamada, 2018; Pöppel and Kopp, 2019) и иррациональных агентов (Zhi- Сюань и др., 2020), и мы также можем использовать его для расширения нашего алгоритма. Конечно, есть и другие теории Теории Разума. Например, Аналогическая теория разума (Рабкина и Форбус, 2019) пытается смоделировать теорию разума посредством изучения структурных знаний. Одним из преимуществ байесовской теории сознания является то, что с ее помощью легко рассчитать поведение, о котором люди могут догадаться, просто разработав простую байесовскую формулу.
Например, исследователи использовали байесовский подход для моделирования того, как люди обучают понятию предмета, показывая предмет учащимся (Shafto et al., 2014). В другом исследовании байесовский подход использовался для моделирования того, как люди учат своих поведенческих предпочтений путем демонстрации (Ho et al., 2016). Обширные доказательства такого рода привели ко многим вариациям когнитивной модели человека, основанной на байесовской теории разума, например, для эгоцентричных агентов (Nakahashi and Yamada, 2018; Pöppel and Kopp, 2019) и иррациональных агентов (Zhi- Сюань и др., 2020), и мы также можем использовать его для расширения нашего алгоритма. Конечно, есть и другие теории Теории Разума. Например, Аналогическая теория разума (Рабкина и Форбус, 2019) пытается смоделировать теорию разума посредством изучения структурных знаний. Одним из преимуществ байесовской теории сознания является то, что с ее помощью легко рассчитать поведение, о котором люди могут догадаться, просто разработав простую байесовскую формулу. Это работает в наших интересах, когда речь идет об эффективном «специальном» сотрудничестве.
Это работает в наших интересах, когда речь идет об эффективном «специальном» сотрудничестве.
Чтобы оценить преимущества неявного руководства, мы разработали простую задачу для команды человек-агент и использовали ее для проведения эксперимента с участием. Задача представляет собой задачу преследования-уклонения, аналогичную примеру на рисунке 1. Есть объекты, которые перемещаются в лабиринте, чтобы избежать захвата, и участник пытается захватить один из объектов посредством сотрудничества с автономным агентом. Мы реализовали три типа совместных агентов, описанных выше, для решения проблемы, и участники выполняли небольшие задачи посредством сотрудничества с этими агентами.Результаты показали, что агент неявного руководства смог направить участников к захвату лучшего объекта, позволяя им чувствовать, что они сохраняют автономию.
2 Методы
2.1 Вычислительная модель
2.1.1 Совместная задача
Мы моделируем совместную задачу как децентрализованный частично наблюдаемый марковский процесс принятия решений (Dec-POMDP) (Goldman and Zilberstein, 2004). Это расширение структуры частично наблюдаемого марковского процесса принятия решений (POMDP) для многоагентных установок, которое имеет дело с конкретным случаем, когда все агенты используют одну и ту же функцию вознаграждения частично наблюдаемой стохастической игры (POSG) (Кун и Такер, 1953 г.). ).
Это расширение структуры частично наблюдаемого марковского процесса принятия решений (POMDP) для многоагентных установок, которое имеет дело с конкретным случаем, когда все агенты используют одну и ту же функцию вознаграждения частично наблюдаемой стохастической игры (POSG) (Кун и Такер, 1953 г.). ).
Dec-POMDP определяется в формате
В нашем случае I состоит из агента и человека { i A , i H }, поэтому A состоит из действия человека и действия агента; таким образом, его можно представить как AA×AH.Вдохновленные MOMDP (Ong et al., 2010), мы факторизуем S в наблюдаемый фактор O как положение агента и человека, а ненаблюдаемый фактор — это цель , которая формально определяет цель человека для задачи как S =О×Θ. В результате наблюдения становятся равными наблюдаемым факторам состояний, формально Ω=O, и T можно разложить на наблюдаемую часть состояния TO:O×Ah×Aa→O и ненаблюдаемую часть состояния TΘ:S→Θ.
В результате наблюдения становятся равными наблюдаемым факторам состояний, формально Ω=O, и T можно разложить на наблюдаемую часть состояния TO:O×Ah×Aa→O и ненаблюдаемую часть состояния TΘ:S→Θ.
2.1.2 Планирование агента
Мы формализуем задачу планирования для расчета действий агента для задачи совместной задачи, описанной выше.В этой формализации пространство действия фокусируется только на действии агента, а цель может быть изменена только человеком посредством наблюдения за действиями агента. Кроме того, мы интегрируем человеческую политику для принятия решения о человеческом действии в функцию перехода. В результате задача планирования агента сводится к POMDP (Kaelbling et al., 1998), который определяется в формате 
Мы предполагаем, что политика человека основана на больцмановской рациональности:
p(aH|o,aA;θ)=exp(β1Q(o,aA,aH;θ))∑θ′∈Θexp(β1Q(o , ах, ах; θ ‘)) (1)где β 1 — это рациональный параметр и Q ( O , A A , A H ; θ ) — функция ценности действия задачи, данной θ .Θ — единственный ненаблюдаемый фактор для состояний, поэтому задача сводится к MDP при заданном Θ. Таким образом, мы можем вычислить Q ( o , a A , a H ; a H ; θ ;
На основе этой формулировки мы формулируем алгоритм планирования для трех взаимодействующих агентов. Разница заключается в функции политики человека, которая представляет собой предположение агента о человеческом поведении.Это различие и составляет основу совместной стратегии.
2.1.2.1 Вспомогательный агент
Вспомогательный агент предполагает, что люди не меняют свою цель независимо от действий агента. То есть TΘ:p(θ′|o,θ,aA)=I(θ=θ′). I — индикаторная функция.
2.1.2.2 Агент явного руководства
Агент явного руководства направляет человека к наилучшей цели; таким образом, предполагается, что человек знает, какая цель является лучшей. Мы представляем лучшую цель как θ *, то есть t θ : 9021 p ( θ ‘| O , θ , A A ) = θ *.Лучшая цель рассчитывается как θ * = agmmax θ ‘∈OT 9122 ( O 0 ; θ ), где O 0 — начальное наблюдаемое состояние и V ( o ; θ ) является функцией значения состояния задачи, заданной θ .
2.1.2.3 Агент неявного управления
Агент неявного управления предполагает, что люди изменяют свою цель, наблюдая за действиями агента. Мы предполагаем, что люди определяют цель агента на основе больцмановской рациональности, как предполагалось в более ранних исследованиях теории разума (Baker et al., 2009) (Baker et al., 2017).
Мы предполагаем, что люди определяют цель агента на основе больцмановской рациональности, как предполагалось в более ранних исследованиях теории разума (Baker et al., 2009) (Baker et al., 2017).
P ( a A | o ,
1 2 9) также основан на больцмановской рациональности:
p(aA|o;θ)=exp(β2V(TO(aA);θ))∑aA′∈AAexp(β2V(TO(aA′);θ))(3 ), где β 2 — рациональный параметр, а V(TO(aA′);θ) — функция значения состояния задачи относительно состояния после a A при заданном θ .
2.1.3 Определение действий агента
Решая POMDP, как показано в 2.1.2, используя общий алгоритм планирования POMDP, мы можем получить набор альфа-векторов, обусловленный наблюдаемым фактором текущего состояния относительно каждого действия. Мы представляем это как Γ a ( o ), и агент совершает наиболее ценное действие aA*. Формально,
Формально,
, где b — текущее мнение о ненаблюдаемом факторе. b обновляется при каждом действии человека и агента следующим образом для каждого ненаблюдаемого фактора уверенности )(5)
Исходное убеждение равно Uniform(Θ) для вспомогательных и неявных агентов руководства и I(θ=θ*) для агента явного руководства.
2.2 Эксперимент
Мы провели эксперимент с участием участников, чтобы изучить преимущества агента неявного управления. Этот эксперимент был одобрен комитетом по этике Национального института информатики.
2.2.1 Совместная постановка задачи
Совместная постановка задачи для нашего эксперимента представляла собой проблему преследования-уклонения (Schenato et al., 2005), которая является типичным типом задачи, используемой для совместной работы человека и агента (Vidal et al. , 2002; Sincák, 2009; Gupta et al., 2017). Эта проблема охватывает основные факторы совместных проблем, то есть то, что человек и агент движутся параллельно и должны общаться для выполнения задачи. Вот почему мы чувствовали, что это будет хорошей основой для понимания человеческого познания.
Вот почему мы чувствовали, что это будет хорошей основой для понимания человеческого познания.
На рис. 3 показан пример нашего экспериментального сценария. В лабиринте есть несколько типов объектов. Желтый квадратный объект с пометкой «P» — это объект, который может перемещать участник, красный квадратный объект с пометкой «A» — это объект, который может перемещать агент, а синие круглые объекты — это целевые объекты, которые участник должен захватить.Когда участники перемещают свой объект, перемещаются целевые объекты и перемещается агент. Целевые объекты перемещаются, чтобы не быть захваченными, и участник, и агент знают об этом. Однако конкретный алгоритм целевых объектов известен только агенту. Так как и участники, и целевые объекты имеют одинаковые возможности для движения, участники не могут самостоятельно захватывать какие-либо целевые объекты. Это означает, что они должны подходить к целевым объектам с обеих сторон за счет взаимодействия с агентом, а участник и агент не могут перемещаться в точки, через которые они уже прошли. Для этого сотрудничества человек и агент должны заранее сообщить друг другу, какой объект они хотят захватить. В эксперименте имеются два целевых объекта, расположенных в разных проходах. Количество шагов, необходимых для захвата каждого объекта, различно, но людям трудно судить об этом. Таким образом, задача будет более успешной, если агент покажет участнику, какой целевой объект является лучшим. В примере на рисунке нижний проход короче верхнего, но имеет путь для побега.Сможет ли нижний объект достичь пути до того, как агент сможет его захватить, является ключевой информацией для принятия решения о том, на какой объект следует нацеливаться. Людям трудно определить это мгновенно, но легко агентам. Существует три возможных пути из начальной точки агента. Центральный — самый короткий для каждого объекта, а остальные — обходные пути для неявного руководства. Кроме того, для усиления эффекта руководства участникам и агентам запрещено двигаться назад.
Для этого сотрудничества человек и агент должны заранее сообщить друг другу, какой объект они хотят захватить. В эксперименте имеются два целевых объекта, расположенных в разных проходах. Количество шагов, необходимых для захвата каждого объекта, различно, но людям трудно судить об этом. Таким образом, задача будет более успешной, если агент покажет участнику, какой целевой объект является лучшим. В примере на рисунке нижний проход короче верхнего, но имеет путь для побега.Сможет ли нижний объект достичь пути до того, как агент сможет его захватить, является ключевой информацией для принятия решения о том, на какой объект следует нацеливаться. Людям трудно определить это мгновенно, но легко агентам. Существует три возможных пути из начальной точки агента. Центральный — самый короткий для каждого объекта, а остальные — обходные пути для неявного руководства. Кроме того, для усиления эффекта руководства участникам и агентам запрещено двигаться назад.
РИСУНОК 3 . Пример эксперимента.
Пример эксперимента.
2.2.1.1 Модель
Мы смоделировали задачу как совместную постановку задачи. Пространство действий соответствует действию агента, а наблюдаемое состояние соответствует позициям участника, агента и целевых объектов. Параметр вознаграждения обусловлен целевым объектом, к которому стремится человек. Пространство параметра соответствует количеству целевых объектов, т. е. |Θ| = 2. Награда за захват правильного/неправильного объекта для θ составляет 100, –100, а стоимость одношагового действия – –1.Поскольку действие «возврат» запрещено, мы можем сжать несколько шагов в одно действие, чтобы человек или агент могли достичь любого соединения. Таким образом, конечное пространство действий представляет собой сжатую последовательность действий, а стоимость равна –1 × количество сжатых шагов. Кроме того, чтобы запретить недопустимые действия, такие как удар головой о стену, мы назначаем такому действию награду -1000. Мы смоделировали три типа взаимодействующих агентов, как обсуждалось выше: поддерживающий агент, агент явного руководства и агент неявного руководства. Мы устанавливаем рациональные параметры как β 1 = 1.0, β 2 = 5,0, а ставка дисконтирования равна 0,99.
Мы устанавливаем рациональные параметры как β 1 = 1.0, β 2 = 5,0, а ставка дисконтирования равна 0,99.
2.2.1.2 Гипотеза
Целью этого эксперимента было определить, может ли неявное руководство направлять людей, позволяя им сохранять автономию. Таким образом, мы проверили следующие две гипотезы.
• (h2) Неявное руководство может направлять решения людей в сторону улучшения сотрудничества.
• (h3) Неявное руководство может помочь людям сохранить автономию больше, чем явное руководство.
2.2.1.3 Задания
Мы подготовили пять заданий. Две из этих задач, перечисленных ниже, были уловками, чтобы людям было трудно решить, какая из них будет лучшей целью. Все задания показаны в дополнительном материале.
• (A) Было два извилистых прохода разной, но одинаковой длины. Для этого типа было три задания.
• (B) Как показано на рис. 3, был длинный проход и короткий путь к выходу. Для этого типа было две задачи.
2.2.1.4 Участники
Мы набрали участников для этого исследования из Yahoo! Краудсорсинг. Участниками были 100 взрослых жителей Японии (70 мужчин, 24 женщины, 6 неизвестных). Средний возраст участников, ответивших на анкету, которую мы использовали, составлял 45 лет.
2.2.1.5 Процедура эксперимента
Наш эксперимент был основан на внутрисубъектном дизайне и проводился в Интернете с использованием созданного нами браузерного приложения. Участники были проинструктированы о правилах поведения агента, а затем прошли подтверждающий тест, чтобы определить степень их понимания.Участникам, которые, как было установлено, не поняли правила, снова дали инструкции. После прохождения этого теста участники перешли к фактической фазе эксперимента. На этом этапе участникам показывали окружающую среду и спрашивали: «Куда вы хотите пойти?» После ввода желаемого действия и агент, и целевые объекты переместились на один шаг вперед. Этот процесс продолжался до тех пор, пока участники не достигли целевого объекта или не ввели определенное количество шагов. Когда каждое задание было выполнено, участники переходили к следующему.Всего участникам было показано 17 заданий, состоящих из 15 обычных заданий и двух фиктивных, чтобы проверить, поняли ли они инструкции. Обычные задачи состояли из трех наборов задач (соответствующих трем совместным агентам), каждый из которых включал по пять задач (соответствующих вариантам задач). Порядок наборов и порядок заданий в каждом наборе были рандомизированы для каждого участника. После того, как участники завершили каждый набор, мы дали им опрос о воспринимаемом взаимодействии с агентом (алгоритм) с использованием 7-балльной шкалы Лайкерта.
Когда каждое задание было выполнено, участники переходили к следующему.Всего участникам было показано 17 заданий, состоящих из 15 обычных заданий и двух фиктивных, чтобы проверить, поняли ли они инструкции. Обычные задачи состояли из трех наборов задач (соответствующих трем совместным агентам), каждый из которых включал по пять задач (соответствующих вариантам задач). Порядок наборов и порядок заданий в каждом наборе были рандомизированы для каждого участника. После того, как участники завершили каждый набор, мы дали им опрос о воспринимаемом взаимодействии с агентом (алгоритм) с использованием 7-балльной шкалы Лайкерта.
Опрос состоял из вопросов, перечисленных ниже.
1. Легко ли было сотрудничать с этим агентом?
2. Вы чувствовали инициативу при работе с этим агентом?
3. Сможете ли вы легко найти целевой объект этого агента?
4. Вы чувствовали, что этот агент предположил ваши намерения?
Пункт два — главный вопрос, так как он касается предполагаемой автономии, которую мы хотим подтвердить. Дополнительные элементы предназначены для предотвращения предвзятых ответов и связаны с другими важными переменными для взаимодействия человека и агента (робота).Первый пункт относится к воспринимаемой простоте сотрудничества, а именно к его беглости, которая в последние годы стала важной качественной переменной в исследованиях взаимодействия человека и робота (Hoffman, 2019). Третий пункт относится к воспринимаемому выводу человека о намерениях агента. Это одна из переменных, ориентированных на прозрачность агента, которая играет ключевую роль в формировании доверия человека к агенту (Lewis et al., 2021). С точки зрения конкретного алгоритма ожидается более высокая оценка для агентов руководства (особенно агентов явного руководства), чем для поддерживающих агентов.Четвертый пункт относится к предполагаемому выводу агента о намерениях человека. Это ключевой элемент предполагаемого рабочего альянса (Hoffman, 2019), и когда он работает бесперебойно, он повышает воспринимаемую адаптивность при взаимодействии человека и агента.
Дополнительные элементы предназначены для предотвращения предвзятых ответов и связаны с другими важными переменными для взаимодействия человека и агента (робота).Первый пункт относится к воспринимаемой простоте сотрудничества, а именно к его беглости, которая в последние годы стала важной качественной переменной в исследованиях взаимодействия человека и робота (Hoffman, 2019). Третий пункт относится к воспринимаемому выводу человека о намерениях агента. Это одна из переменных, ориентированных на прозрачность агента, которая играет ключевую роль в формировании доверия человека к агенту (Lewis et al., 2021). С точки зрения конкретного алгоритма ожидается более высокая оценка для агентов руководства (особенно агентов явного руководства), чем для поддерживающих агентов.Четвертый пункт относится к предполагаемому выводу агента о намерениях человека. Это ключевой элемент предполагаемого рабочего альянса (Hoffman, 2019), и когда он работает бесперебойно, он повышает воспринимаемую адаптивность при взаимодействии человека и агента. Воспринимаемая адаптивность положительно влияет на воспринимаемую полезность и воспринимаемое удовольствие (Shin and Choo, 2011). С точки зрения конкретного алгоритма ожидается более высокий балл для агентов без неявного руководства (особенно поддерживающих агентов), чем для агентов неявного руководства.
Воспринимаемая адаптивность положительно влияет на воспринимаемую полезность и воспринимаемое удовольствие (Shin and Choo, 2011). С точки зрения конкретного алгоритма ожидается более высокий балл для агентов без неявного руководства (особенно поддерживающих агентов), чем для агентов неявного руководства.
3 результата
Перед анализом результатов мы исключили все данные участников, которые были признаны недействительными. Для этой цели мы использовали фиктивные задачи, которые были простыми задачами, у которых был только один действительный целевой объект. Затем мы отфильтровали результаты участников (всего трое), которые не выполнили эти фиктивные задания.
3.1 Результаты совместной задачи
На рис. 4 показана скорость, с которой участники захватили лучший объект, известный агенту. Другими словами, это показатель успешности руководства агента на основе любого из данных указаний.Мы проверили данные в соответствии со стандартным процессом парного тестирования. Результаты дисперсионного анализа с повторными измерениями (ANOVA) показали, что существует статистически значимое различие между типами агентов для общих задач ( F (2, 968) = 79,9, p = 7,4 e — 33) , тип задачи (A) ( F (2, 580) = 55,9, p = 5,9 e − 23) и тип задачи (B) ( F (2, 386) = 24,7, p = 7,5 e — 11).Затем мы выполнили повторные измерения t-тестов с поправкой Бонферрони, чтобы определить, какие два агента имели статистически значимое различие. «**» на рисунке означает, что между двумя оценками были значительные различия ( p ≪ 0,01). Результаты показывают среднюю скорость для общих задач, типа задачи (A) и типа задачи (B). Все результаты были схожими, что свидетельствует о том, что производительность не зависела от типа задачи. Задача сотрудничества с поддерживающим агентом явно имела низкий уровень.Это указывает на то, что задача была достаточно сложной, чтобы участникам было трудно решить, какой объект лучше, и руководство агента было ценным для улучшения выполнения этой задачи.
Результаты дисперсионного анализа с повторными измерениями (ANOVA) показали, что существует статистически значимое различие между типами агентов для общих задач ( F (2, 968) = 79,9, p = 7,4 e — 33) , тип задачи (A) ( F (2, 580) = 55,9, p = 5,9 e − 23) и тип задачи (B) ( F (2, 386) = 24,7, p = 7,5 e — 11).Затем мы выполнили повторные измерения t-тестов с поправкой Бонферрони, чтобы определить, какие два агента имели статистически значимое различие. «**» на рисунке означает, что между двумя оценками были значительные различия ( p ≪ 0,01). Результаты показывают среднюю скорость для общих задач, типа задачи (A) и типа задачи (B). Все результаты были схожими, что свидетельствует о том, что производительность не зависела от типа задачи. Задача сотрудничества с поддерживающим агентом явно имела низкий уровень.Это указывает на то, что задача была достаточно сложной, чтобы участникам было трудно решить, какой объект лучше, и руководство агента было ценным для улучшения выполнения этой задачи. Эти результаты являются убедительным доказательством в поддержку гипотезы h2. Еще один интересный момент: не было существенной разницы в частоте между неявным и явным руководством. Хотя мы не объясняли участникам неявное руководство, они все равно догадывались о намерении агента и использовали его в качестве руководства.Конечно, вероятной причиной этого является то, что задача была настолько простой, что участники могли легко сделать вывод о намерениях агента. Однако тот факт, что неявное руководство почти так же эффективно, как и явное, в таких простых задачах впечатляет.
Эти результаты являются убедительным доказательством в поддержку гипотезы h2. Еще один интересный момент: не было существенной разницы в частоте между неявным и явным руководством. Хотя мы не объясняли участникам неявное руководство, они все равно догадывались о намерении агента и использовали его в качестве руководства.Конечно, вероятной причиной этого является то, что задача была настолько простой, что участники могли легко сделать вывод о намерениях агента. Однако тот факт, что неявное руководство почти так же эффективно, как и явное, в таких простых задачах впечатляет.
РИСУНОК 4 . Средняя скорость захвата лучшего объекта.
3.2 Результаты воспринимаемого взаимодействия с агентом
На рис. 5 показаны результаты опроса о влиянии агента на познание. Результаты повторных измерений ANOVA показали, что существовала статистически значимая разница между типами агентов в воспринимаемой простоте сотрудничества ( F (2, 192) = 29.8, p = 5,4 e − 12), воспринимаемая автономия ( F (2, 192) = 36,4, p = 4,1 e − 14) и воспринимаемое умозаключение о намерениях человека ( F (2, 192) = 49,7, p = 4,0 e — 18). Напротив, не было статистически значимой разницы для пункта опроса, воспринимаемого как вывод о намерениях агента ( F (2, 192) = 1,8, p = 0,167). Затем мы выполнили повторные измерения t-тестов с поправкой Бонферрони, чтобы определить, какие два агента имели статистически значимую разницу в отношении переменных, которые имеют значимую разницу.«**» на рисунке означает, что между двумя оценками были значительные различия ( p ≪ 0,01). Наиболее важным результатом здесь является оценка воспринимаемой автономии. Из этого результата мы видим, что участники чувствовали, что у них больше автономии во время выполнения задач при сотрудничестве с агентом неявного руководства, чем с агентом явного руководства. Эти результаты являются убедительным доказательством в поддержку гипотезы h3.
Напротив, не было статистически значимой разницы для пункта опроса, воспринимаемого как вывод о намерениях агента ( F (2, 192) = 1,8, p = 0,167). Затем мы выполнили повторные измерения t-тестов с поправкой Бонферрони, чтобы определить, какие два агента имели статистически значимую разницу в отношении переменных, которые имеют значимую разницу.«**» на рисунке означает, что между двумя оценками были значительные различия ( p ≪ 0,01). Наиболее важным результатом здесь является оценка воспринимаемой автономии. Из этого результата мы видим, что участники чувствовали, что у них больше автономии во время выполнения задач при сотрудничестве с агентом неявного руководства, чем с агентом явного руководства. Эти результаты являются убедительным доказательством в поддержку гипотезы h3.
РИСУНОК 5 . Средняя оценка опроса о воспринимаемом взаимодействии с агентом.
Хотя другие результаты не имеют прямого отношения к нашей гипотезе, мы кратко остановимся на их анализе. Что касается предполагаемого вывода о намерениях человека, результаты были в основном такими, как и ожидалось, но для предполагаемого вывода о намерениях агента тот факт, что между всеми агентами не было существенных различий, оказался неожиданным. Одна из гипотез, объясняющая это, состоит в том, что люди не распознают информацию наведения как намерение агента. Что касается воспринимаемой простоты сотрудничества, результаты показали, что явное руководство оказывает на нее неблагоприятное воздействие.Агенты неявного руководства и вспомогательные агенты используют точно такой же интерфейс, хотя алгоритмы различаются, но агенты явного руководства используют немного другой интерфейс для передачи руководства, что немного увеличивает объем информации в интерфейсе. Мы считаем, что бремя понимания такой дополнительной видимой информации может быть причиной негативного влияния на воспринимаемую легкость сотрудничества.
Что касается предполагаемого вывода о намерениях человека, результаты были в основном такими, как и ожидалось, но для предполагаемого вывода о намерениях агента тот факт, что между всеми агентами не было существенных различий, оказался неожиданным. Одна из гипотез, объясняющая это, состоит в том, что люди не распознают информацию наведения как намерение агента. Что касается воспринимаемой простоты сотрудничества, результаты показали, что явное руководство оказывает на нее неблагоприятное воздействие.Агенты неявного руководства и вспомогательные агенты используют точно такой же интерфейс, хотя алгоритмы различаются, но агенты явного руководства используют немного другой интерфейс для передачи руководства, что немного увеличивает объем информации в интерфейсе. Мы считаем, что бремя понимания такой дополнительной видимой информации может быть причиной негативного влияния на воспринимаемую легкость сотрудничества.
4 Обсуждение
Насколько нам известно, это первое исследование, демонстрирующее, что неявное руководство имеет преимущества как с точки зрения выполнения задачи, так и с точки зрения влияния агента на воспринимаемую автономию человека в командах человек-агент. В этом разделе мы обсудим, как наши результаты соотносятся с другими исследованиями, текущими ограничениями и будущими направлениями.
В этом разделе мы обсудим, как наши результаты соотносятся с другими исследованиями, текущими ограничениями и будущими направлениями.
4.1 Обсуждение результатов
Результаты в 3.1 показывают, что как неявное, так и явное руководство увеличивает вероятность успеха совместной задачи. Мы считаем, что одной из причин этого является надлежащее качество информации в руководстве. Предыдущее исследование взаимосвязи между типом информации и совместным выполнением задач Butchibabu et al. (2016) показали, что «неявная координация» улучшает выполнение задачи больше, чем «явная координация» в совместной задаче.Слово «неявный» относится к координации, которая «основана на прогнозировании потребностей в информации и ресурсах других членов команды». Это определение отличается от нашего, поскольку «неявная координация» включена в явное руководство в нашем контексте. В этом исследовании «неявная координация» была далее разделена на «совещательную коммуникацию», которая включает в себя сообщение целей, и «реактивную коммуникацию», которая включает в себя общение в ситуациях, и утверждалось, что высокопроизводительные команды с большей вероятностью будут использовать первый тип коммуникации, чем последний. .Мы чувствуем, что качество информации в неявном руководстве в нашем контексте такое же, как и в этом совещательном общении, поскольку оно передает желаемую цель, что является одной из причин, по которой наше руководство может обеспечить хорошую работу.
.Мы чувствуем, что качество информации в неявном руководстве в нашем контексте такое же, как и в этом совещательном общении, поскольку оно передает желаемую цель, что является одной из причин, по которой наше руководство может обеспечить хорошую работу.
Главной задачей команд человек-агент является повышение производительности при выполнении задач. Однако, поскольку было проведено не так много исследований, посвященных влиянию агента на познание, результаты в 3.2 должны внести хороший вклад в исследования групп человек-агент.В одном из немногих проведенных исследований изучалось выполнение задачи и предпочтения людей в отношении совместной задачи с участием человека и агента ИИ (Gombolay et al., 2015). В этом исследовании авторы упомянули о риске того, что работник с роботом-сотрудником может работать хуже из-за потери автономии, что мы также рассмотрели в нашей работе. Они обнаружили, что полуавтономная настройка, в которой человек сначала решает, какие задачи он хочет выполнить, а агент затем решает остальные назначения задач, удовлетворяет больше, чем ручное управление и настройки автономного управления, в которых человек и робот полностью распределяет задачи. В сотрудничестве с агентом неявного руководства и агентом поддержки в нашем исследовании человек сам выбирает желаемого персонажа. Это можно рассматривать как своего рода полуавтономную настройку. Таким образом, наши результаты согласуются с этими в том смысле, что участники твердо считали, что сотрудничество было проще, чем с явными агентами руководства. Кроме того, в этом исследовании также упоминается, что эффективность задачи положительно влияет на удовлетворенность людей, что также согласуется с нашими результатами.
В сотрудничестве с агентом неявного руководства и агентом поддержки в нашем исследовании человек сам выбирает желаемого персонажа. Это можно рассматривать как своего рода полуавтономную настройку. Таким образом, наши результаты согласуются с этими в том смысле, что участники твердо считали, что сотрудничество было проще, чем с явными агентами руководства. Кроме того, в этом исследовании также упоминается, что эффективность задачи положительно влияет на удовлетворенность людей, что также согласуется с нашими результатами.
4.2 Ограничение и будущее направление
Наша текущая работа имеет ограничения, заключающиеся в том, что экспериментальная среда была небольшой и простой, модель намерения представляла собой небольшой дискретный набор целей, а пространство действий агента представляло собой небольшой дискретный набор. В реальной среде существует большое разнообразие человеческих намерений, таких как целевые приоритеты и предпочтения в действиях. Результаты в этой статье не показывают, является ли наш подход достаточно масштабируемым для задач с такой сложной структурой намерения. Кроме того, пространство действий агента представляло собой небольшой дискретный набор, который люди могли различить, что облегчало человеку вывод о намерениях агента. Это усиливает преимущество неявного руководства, поэтому наши результаты не обязательно гарантируют такое же преимущество для сред с непрерывным пространством действий. Расширение модели намерения до более гибкой структуры было бы наиболее важным направлением нашего будущего исследования. Одним из наиболее многообещающих подходов является интеграция с исследованиями по обучению с обратным подкреплением (Ng and Russell, 2000).Обратное обучение с подкреплением — это задача оценки функции вознаграждения, лежащей в основе поведения, по поведению других. Оценка намерения и цели на основе байесовской теории разума также может рассматриваться как своего рода обучение с обратным подкреплением (Jara-Ettinger, 2019). Обучение с обратным подкреплением было исследовано для различных моделей вознаграждения (Abbeel and Ng, 2004; Levine et al.
Кроме того, пространство действий агента представляло собой небольшой дискретный набор, который люди могли различить, что облегчало человеку вывод о намерениях агента. Это усиливает преимущество неявного руководства, поэтому наши результаты не обязательно гарантируют такое же преимущество для сред с непрерывным пространством действий. Расширение модели намерения до более гибкой структуры было бы наиболее важным направлением нашего будущего исследования. Одним из наиболее многообещающих подходов является интеграция с исследованиями по обучению с обратным подкреплением (Ng and Russell, 2000).Обратное обучение с подкреплением — это задача оценки функции вознаграждения, лежащей в основе поведения, по поведению других. Оценка намерения и цели на основе байесовской теории разума также может рассматриваться как своего рода обучение с обратным подкреплением (Jara-Ettinger, 2019). Обучение с обратным подкреплением было исследовано для различных моделей вознаграждения (Abbeel and Ng, 2004; Levine et al. , 2011; Choi and Kim, 2014; Wulfmeier et al., 2015), а также было предложено справляться с неопределенностью информации о конкретном вознаграждение (Hadfield-Menell et al., 2017). Наконец, что касается простоты нашей экспериментальной среды, использование сред, разработанных в соответствии с объективным фактором сложности (Wood, 1986), а затем анализ взаимосвязи между эффективностью неявного руководства и сложностью среды было бы интересным направлением для будущего. работай.
, 2011; Choi and Kim, 2014; Wulfmeier et al., 2015), а также было предложено справляться с неопределенностью информации о конкретном вознаграждение (Hadfield-Menell et al., 2017). Наконец, что касается простоты нашей экспериментальной среды, использование сред, разработанных в соответствии с объективным фактором сложности (Wood, 1986), а затем анализ взаимосвязи между эффективностью неявного руководства и сложностью среды было бы интересным направлением для будущего. работай.
Другим ограничением является предположение, что все люди имеют одну и ту же фиксированную когнитивную модель. Как упоминалось ранее, фиксированная когнитивная модель выгодна для нерегламентированной совместной работы, но для более точной совместной работы важно соответствие индивидуальным когнитивным моделям.Первый подход заключается в параметризации человеческого познания в отношении конкретных когнитивных способностей (рациональность, мышление К-уровня (Nagel, 1995), объем рабочей памяти (Daneman and Carpenter, 1980) и т. д.) и подгонке параметров в режиме онлайн. Это позволило бы персонализировать когнитивные модели с небольшим количеством образцов. Одним из таких подходов является взаимная адаптация человека и робота для «общей автономии», при которой контроль над роботом распределяется между человеком и роботом (Nikolaidis et al., 2017).При таком подходе робот учится «адаптивности», то есть степени, в которой люди меняют свою политику, чтобы приспособиться к контролю робота.
д.) и подгонке параметров в режиме онлайн. Это позволило бы персонализировать когнитивные модели с небольшим количеством образцов. Одним из таких подходов является взаимная адаптация человека и робота для «общей автономии», при которой контроль над роботом распределяется между человеком и роботом (Nikolaidis et al., 2017).При таком подходе робот учится «адаптивности», то есть степени, в которой люди меняют свою политику, чтобы приспособиться к контролю робота.
Наконец, элементы опроса, которые мы использовали для определения влияния агента на воспринимаемую автономию, были общими и субъективными. Для более конкретного и последовательного анализа влияния на воспринимаемую автономию нам необходимо разработать более сложные элементы опроса и дополнительные объективные переменные. Последовательные множественные вопросы для определения автономии человека в общей автономии использовались и раньше (Du et al., 2020). Что касается измерения объективной переменной, то первым выбором будет анализ траекторий в совместной задаче. Хорошим ключом к восприятию автономии траекторий являются «перетасовки». Первоначально перетасовка относилась к любому действию, которое сводит на нет предыдущее действие, например движение влево, а затем вправо, и это также может быть объективной переменной для замешательства человека. Если мы объединим перетасовку с оценкой цели, мы можем разработать переменную «перетасовка для достижения цели». Большее количество переменных означает, что цель человека непостоянна, что, таким образом, означает, что он или она подвержен влиянию других и имеет низкую автономию.Кроме того, время реакции и биометрическая информация, такая как взгляд, также могут быть хорошими кандидатами на роль объективных переменных.
Хорошим ключом к восприятию автономии траекторий являются «перетасовки». Первоначально перетасовка относилась к любому действию, которое сводит на нет предыдущее действие, например движение влево, а затем вправо, и это также может быть объективной переменной для замешательства человека. Если мы объединим перетасовку с оценкой цели, мы можем разработать переменную «перетасовка для достижения цели». Большее количество переменных означает, что цель человека непостоянна, что, таким образом, означает, что он или она подвержен влиянию других и имеет низкую автономию.Кроме того, время реакции и биометрическая информация, такая как взгляд, также могут быть хорошими кандидатами на роль объективных переменных.
Другим ограничением этого исследования является то, что мы предположили, что люди относятся к агенту рационально и действуют только для достижения своих собственных целей. Первое проблематично, потому что на самом деле люди могут не доверять агенту. Одним из подходов к решению этой проблемы является использование модели байесовской теории разума для иррациональных агентов (Zhi-Xuan et al. , 2020). Что касается последнего, в более практической ситуации люди могут предпринять действия, чтобы предоставить агенту информацию, аналогичную неявному руководству.Вспомогательная игра/совместное обучение с обратным подкреплением (CIRL) (Hadfield-Menell et al., 2016) была предложена в качестве проблемы планирования для такого рода человеческого поведения. В этой задаче только человек знает функцию вознаграждения, и агент предполагает, что человек ожидает, что он выведет эту функцию и предпримет действия, чтобы максимизировать вознаграждение. Агент неявно предполагает, что человек предоставит информацию для эффективного совместного планирования. Как правило, CIRL требует больших вычислительных ресурсов, но ее можно решить, немного изменив алгоритм POMDP (Malik et al., 2018), а значит, мы могли бы совместить его с нашим подходом. Это также позволило бы нам рассмотреть более реалистичную и идеальную команду человек-агент, в которой люди и агенты обеспечивают друг друга неявным руководством.
, 2020). Что касается последнего, в более практической ситуации люди могут предпринять действия, чтобы предоставить агенту информацию, аналогичную неявному руководству.Вспомогательная игра/совместное обучение с обратным подкреплением (CIRL) (Hadfield-Menell et al., 2016) была предложена в качестве проблемы планирования для такого рода человеческого поведения. В этой задаче только человек знает функцию вознаграждения, и агент предполагает, что человек ожидает, что он выведет эту функцию и предпримет действия, чтобы максимизировать вознаграждение. Агент неявно предполагает, что человек предоставит информацию для эффективного совместного планирования. Как правило, CIRL требует больших вычислительных ресурсов, но ее можно решить, немного изменив алгоритм POMDP (Malik et al., 2018), а значит, мы могли бы совместить его с нашим подходом. Это также позволило бы нам рассмотреть более реалистичную и идеальную команду человек-агент, в которой люди и агенты обеспечивают друг друга неявным руководством.
Заключение
В этой работе мы продемонстрировали, что совместный агент, основанный на «неявном руководстве», эффективен для обеспечения баланса между улучшением планов человека и сохранением автономии человека. Неявное руководство может направлять поведение человека в сторону лучших стратегий и повышать производительность при выполнении совместных задач.Кроме того, наш подход заставляет людей чувствовать, что у них есть автономия во время выполнения задач, в большей степени, чем когда агент явно направляет их. Мы внедрили агентов на основе неявного руководства, интегрировав модель байесовской теории разума в существующее планирование POMDP, и провели поведенческий эксперимент, в котором люди выполняли простые задачи с автономными агентами. Наши результаты показали, что было много ограничений, таких как плохая информационная модель агента и тривиальная экспериментальная среда. Тем не менее, мы считаем, что наши результаты могут привести к более качественным исследованиям более практичного и удобного для человека взаимодействия человека и агента.
Заявление о доступности данных
Необработанные данные, подтверждающие заключение этой статьи, будут предоставлены авторами без неоправданных оговорок.
Заявление об этике
Исследования с участием людей были рассмотрены и одобрены Комитетом по этике Национального института информатики. Письменное информированное согласие на участие в этом исследовании не требовалось в соответствии с национальным законодательством и институциональными требованиями.
Вклад автора
Р.Н. разработал первоначальную идею, реализовал программу, разработал и провел эксперимент, проанализировал данные и написал рукопись. SY консультировал весь процесс и был соавтором статьи. Все авторы одобрили представленную версию.
Конфликт интересов
Авторы заявляют, что исследование проводилось при отсутствии каких-либо коммерческих или финансовых отношений, которые могли бы быть истолкованы как потенциальный конфликт интересов.
Примечания издателя
Все претензии, изложенные в этой статье, принадлежат исключительно авторам и не обязательно представляют претензии их дочерних организаций или издателя, редакторов и рецензентов. Любой продукт, который может быть оценен в этой статье, или претензии, которые могут быть сделаны его производителем, не гарантируются и не поддерживаются издателем.
Любой продукт, который может быть оценен в этой статье, или претензии, которые могут быть сделаны его производителем, не гарантируются и не поддерживаются издателем.
Дополнительный материал
Дополнительный материал к этой статье можно найти в Интернете по адресу: https://www.frontiersin.org/articles/10.3389/frai.2021.736321/full#supplementary-material
Ссылки
Abbeel, P., and Ng, A.Y. (2004). «Ученичество с помощью обучения с обратным подкреплением», в Трудах двадцать первой международной конференции по машинному обучению (ICML) . Альберта: ACM Press, 1. doi:10.1145/1015330.1015430
CrossRef Полный текст | Google Scholar
Бейкер К.Л., Джара-Эттингер Дж., Сакс Р. и Тененбаум Дж. Б. (2017). Рациональная количественная атрибуция убеждений, желаний и представлений в ментализации человека. Нац. Гум. Поведение 1, 1–10. doi:10.1038/s41562-017-0064
Полный текст CrossRef | Google Scholar
Бутчибабу А., Спарано-Хуибан К. , Соненберг Л. и Шах Дж. (2016). Стратегии неявной координации для эффективного командного общения. Гул. Факторы 58, 595–610. doi:10.1177/0018720816639712
, Соненберг Л. и Шах Дж. (2016). Стратегии неявной координации для эффективного командного общения. Гул. Факторы 58, 595–610. doi:10.1177/0018720816639712
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Кэрролл М., Шах Р., Хо М. К., Гриффитс Т., Сешиа С., Аббил П. и др. (2019).О пользе изучения людей для координации действий человека и искусственного интеллекта. Доп. Нейронная инф. Обработать. Сист. 32, 5174–5185.
Google Scholar
Чакраборти Т., Шридхаран С. и Камбхампати С. (2018). «Возвращение к планированию с осознанием человека: рассказ о трех моделях», в Proc. семинара IJCAI/ECAI 2018 по объяснимому искусственному интеллекту (XAI) (Калифорния: IJCAI). Эта статья была также опубликована в Proc. семинара ICAPS 2018 по объяснимому планированию искусственного интеллекта (XAIP).18–25.
Google Scholar
Данеман М. и Карпентер П. А. (1980). Индивидуальные различия в рабочей памяти и чтении. J. словесный ЖЖ. вербальное поведение. 19, 450–466. doi:10.1016/s0022-5371(80)-6
J. словесный ЖЖ. вербальное поведение. 19, 450–466. doi:10.1016/s0022-5371(80)-6
Полный текст CrossRef | Google Scholar
Де Верд Х., Вербрюгге Р. и Верхей Б. (2013). Насколько полезно знать, что она знает, что ты знаешь? агентное имитационное исследование. Артиф. Разведка 199-200, 67–92. дои: 10.1016 / j.artint.2013.05.004
CrossRef Полный текст | Google Scholar
де Верд Х., Вербрюгге Р. и Верхей Б. (2017). Переговоры с другими разумами: роль рекурсивной теории разума в переговорах с неполной информацией. Автон. Агент Мультиагент Сист. 31, 250–287. doi:10.1007/s10458-015-9317-1
Полный текст CrossRef | Google Scholar
Драган А.Д., Ли К.С. и Шриниваса С.С. (2013). «Разборчивость и предсказуемость движения роботов», , 2013 г., 8-я Международная конференция ACM/IEEE по взаимодействию человека и робота (HRI) (Нью-Джерси: IEEE), 301–308.doi:10.1109/hri.2013.6483603
Полный текст CrossRef | Google Scholar
Драган, А. Д. (2017). Планирование роботов с помощью математических моделей человеческого состояния и действий . Препринт arXiv arXiv:1705.04226 .
Д. (2017). Планирование роботов с помощью математических моделей человеческого состояния и действий . Препринт arXiv arXiv:1705.04226 .
Ду Ю., Темкин С., Кичиман Э., Полани Д., Аббил П. и Драган А. (2020). Ave: Помощь через наделение полномочиями. Доп. Нейронная инф. Обработать. Сист. 33.
Google Scholar
Гмытрасевич, П.Дж., и Доши, П. (2005).Фреймворк для последовательного планирования в многоагентных условиях. джаир 24, 49–79. doi:10.1613/jair.1579
Полный текст CrossRef | Google Scholar
Goldman, C.V., and Zilberstein, S. (2004). Децентрализованное управление кооперативными системами: Категоризация и анализ сложности. джаир 22, 143–174. doi:10.1613/jair.1427
Полный текст CrossRef | Google Scholar
Гомболей М., Баир А., Хуанг С. и Шах Дж. (2017). Вычислительный дизайн совместной работы человека и робота со смешанной инициативой, который учитывает человеческий фактор: ситуационную осведомленность, рабочую нагрузку и предпочтения рабочего процесса. Междунар. Дж. Робототехника Рез. 36, 597–617. doi:10.1177/0278364916688255
Междунар. Дж. Робототехника Рез. 36, 597–617. doi:10.1177/0278364916688255
Полный текст CrossRef | Google Scholar
Гомболей, М. К., Гутьеррес, Р. А., Кларк, С. Г., Стурла, Г. Ф., и Шах, Дж. А. (2015). Полномочия по принятию решений, эффективность команды и удовлетворенность человека работником в смешанных командах человек-робот. Автон. Робот 39, 293–312. doi:10.1007/s10514-015-9457-9
Полный текст CrossRef | Google Scholar
Гупта Дж. К., Егоров М., Кохендерфер М.(2017). «Совместное многоагентное управление с использованием глубокого обучения с подкреплением», Международная конференция по автономным агентам и мультиагентным системам (Берлин: Springer), 66–83. doi:10.1007/978-3-319-71682-4_5
CrossRef Full Text | Google Scholar
Хэдфилд-Менелл Д., Милли С., Аббил П., Рассел С. и Драган А. (2017). Обратный дизайн вознаграждения. Доп. Нейронная инф. Обработать. Сист. 30, 6765–6774.
Google Scholar
Хэдфилд-Менелл, Д. , Рассел С.Дж., Аббил П. и Драган А. (2016). Совместное обучение с обратным подкреплением. Доп. Нейронная инф. Обработать. Сист. 29, 3909–3917.
, Рассел С.Дж., Аббил П. и Драган А. (2016). Совместное обучение с обратным подкреплением. Доп. Нейронная инф. Обработать. Сист. 29, 3909–3917.
Google Scholar
Хо, М. К., Литтман, М., Макглашан, Дж., Кушман, Ф., и Аустервейл, Дж. Л. (2016). Демонстрация против действия: обучение посредством демонстрации. Доп. Нейронная инф. Обработать. Сист. 29, 3027–3035.
Google Scholar
Хоффман, Г. (2019). Оценка беглости в сотрудничестве человека и робота. IEEE Trans. Человек-мах. Сист. 49, 209–218. doi:10.1109/thms.2019.28
Полный текст CrossRef | Google Scholar
Жак Н., Лазариду А., Хьюз Э., Гюльчере Ч., Ортега П. А., Страус Д. и др. (2018). Внутренняя социальная мотивация через каузальное влияние в мультиагентном rl. corr abs/1810 , 08647. Препринт arXiv arXiv:1810.08647 .
Хара-Эттингер, Дж. (2019). Теория разума как обучение с обратным подкреплением. Курс. мнениеПоведение науч. 29, 105–110. doi:10.1016/j.cobeha.2019.04.010
29, 105–110. doi:10.1016/j.cobeha.2019.04.010
Полный текст CrossRef | Google Scholar
Kaelbling, LP, Littman, ML, and Cassandra, AR (1998). Планирование и действия в частично наблюдаемых стохастических областях. Артиф. разведка 101, 99–134. doi:10.1016/s0004-3702(98)00023-x
Полный текст CrossRef | Google Scholar
Камар Э., Галь Ю. и Гросс Б. Дж. (2009). «Включение полезного поведения в совместное планирование», в материалах 8-й Международной конференции по автономным агентам и мультиагентным системам (AAMAS) (Берлин: Springer-Verlag).
Google Scholar
Кун, Х.В., и Такер, А.В. (1953). Вклад в теорию игр , Vol. 2. Нью-Джерси: Издательство Принстонского университета.
Левин С., Попович З. и Колтун В. (2011). Нелинейное обучение с обратным подкреплением с гауссовыми процессами. Доп. Нейронная инф. Обработать. Сист. 24, 19–27.
Google Scholar
Льюис М., Ли Х. и Сикара К. (2021). Глубокое обучение, прозрачность и доверие к командной работе человека-робота. Доверие к взаимодействию человека и робота (Elsevier) , 321–352. doi:10.1016/b978-0-12-819472-0.00014-9
(2021). Глубокое обучение, прозрачность и доверие к командной работе человека-робота. Доверие к взаимодействию человека и робота (Elsevier) , 321–352. doi:10.1016/b978-0-12-819472-0.00014-9
Полный текст CrossRef | Google Scholar
Macindoe, O., Kaelbling, LP, and Lozano-Pérez, T. (2012). «Pomcop: Планирование пространства убеждений для помощников в совместных играх», Восьмая конференция по искусственному интеллекту и интерактивным цифровым развлечениям .
Google Scholar
Малик Д., Паланиаппан М., Фисак Дж., Хэдфилд-Менелл Д., Рассел С.и Драган, А. (2018). .Эффективное обобщенное обновление Беллмана для совместного обучения с обратным подкреплением. Международная конференция по машинному обучению . (AIIDE) Калифорния: AAAI, 3394–3402.
Google Scholar
Нагель, Р. (1995). Разгадка в играх на угадывание: экспериментальное исследование. утра. Экон. Ред. 85, 1313–1326.
Google Scholar
Накахаши Р. и Ямада С. (2018). Моделирование человеческого вывода о намерениях других в сложных ситуациях с уклоном на предсказуемость плана .Препринт arXiv arXiv: 1805.06248.
и Ямада С. (2018). Моделирование человеческого вывода о намерениях других в сложных ситуациях с уклоном на предсказуемость плана .Препринт arXiv arXiv: 1805.06248.
Нг, А.Ю., и Рассел, С.Дж. (2000). «Алгоритмы обучения с обратным подкреплением», в материалах 40-й ежегодной конференции Общества когнитивных наук, Cogsci (Висконсин: CogSci/ICCS) 1, 2147–2152.
Google Scholar
Николаидис С., Нат С., Прокачча А. Д. и Шриниваса С. (2017). «Теоретико-игровое моделирование адаптации человека при сотрудничестве человека и робота», в материалах Международной конференции ACM/IEEE 2017 г. по взаимодействию человека и робота (Нью-Джерси: IEEE), 323–331.doi:10.1145/2
4.3020253
CrossRef Полный текст | Google Scholar
Ong, S.C.W., Shao Wei Png, S.W., Hsu, D. и Wee Sun Lee, WS (2010). Планирование в условиях неопределенности для роботизированных задач со смешанной наблюдаемостью. Междунар. Дж. Робототехника Рез. 29, 1053–1068. doi:10. 1177/0278364
1177/0278364
9861
Полный текст CrossRef | Google Scholar
Пёппель Дж. и Копп С. (2019). Эгоцентрические тенденции в теории мышления разума: эмпирический и вычислительный анализ. CogSci , 2585–2591.
Google Scholar
Рабкина И. и Форбус К. Д. (2019). «Аналогическое рассуждение для распознавания намерений и прогнозирования действий в многоагентных системах», в материалах Седьмой ежегодной конференции по достижениям в когнитивных системах . Кембридж: Фонд когнитивных систем, 504–517.
Google Scholar
Щенато, Л., О, С., Састри, С., и Бозе, П. (2005). «Координация роя для игр с уклонением от преследования с использованием сенсорных сетей», в материалах Proceedings of the 2005 IEEE International Conference on Robotics and Automation (Нью-Джерси: IEEE), 2493–2498.
Google Scholar
Шафто П., Гудман Н. Д. и Гриффитс Т. Л. (2014). Рациональное объяснение педагогического мышления: обучение на примерах и обучение на них. Познан. Психол. 71, 55–89. doi:10.1016/j.cogpsych.2013.12.004
Познан. Психол. 71, 55–89. doi:10.1016/j.cogpsych.2013.12.004
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Шин Д.-Х. и Чу Х. (2011). Моделирование принятия социально интерактивной робототехники. Есть 12, 430–460. doi:10.1075/is.12.3.04shi
Полный текст CrossRef | Google Scholar
Синчак, Д.(2009). Многороботная система управления для задачи преследования-уклонения. Дж. Электр. англ. 60, 143–148.
Google Scholar
Стоун П., Каминка Г. А., Краус С. и Розеншайн Дж. С. (2010). «Специальные группы автономных агентов: сотрудничество без предварительной координации», Двадцать четвертая конференция AAAI по искусственному интеллекту (Калифорния: AAAI).
Google Scholar
Страус Д., Клейман-Вайнер М., Тененбаум Дж., Ботвиник М. и Шваб Д.(2018). Обучение делиться и скрывать намерения с помощью регуляризации информации . Препринт arXiv arXiv: 1808.02093.
Таха Т. , Миро Дж. В. и Диссанаяке Г. (2011). Фреймворк pomdp для моделирования взаимодействия человека с вспомогательными роботами. В Доп. Нейронная инф. Обработать. Сист. 31, 544–549. doi:10.1109/icra.2011.5980323
, Миро Дж. В. и Диссанаяке Г. (2011). Фреймворк pomdp для моделирования взаимодействия человека с вспомогательными роботами. В Доп. Нейронная инф. Обработать. Сист. 31, 544–549. doi:10.1109/icra.2011.5980323
Полный текст CrossRef | Google Scholar
Видаль Р., Шакерния О., Ким Х. Дж., Шим Д. Х. и Састри С. (2002). Вероятностные игры преследования-уклонения: теория, реализация и экспериментальная оценка. IEEE Trans. Робот. Автомат. 18, 662–669. doi:10.1109/tra.2002.804040
Полный текст CrossRef | Google Scholar
Wood, RE (1986). Сложность задачи: Определение конструкции. Организационное поведение. Гум. Реш. Обработать. 37, 60–82. doi:10.1016/0749-5978(86)
-0Полный текст CrossRef | Google Scholar
Ву, С. А., Ван, Р. Э., Эванс, Дж. А., Тененбаум, Дж. Б., Паркс, Д. К., и Клейман-Вайнер, М. (2021). Слишком много поваров: байесовский вывод для координации многоагентного сотрудничества. Верх. Познан. науч. 13, 414–432. doi:10.1111/tops.12525
doi:10.1111/tops.12525
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Вульфмайер М., Ондруска П. и Познер И. (2015). Максимальная энтропия глубокого обратного обучения с подкреплением . Препринт arXiv arXiv:1507.04888 .
Чжи-Суан, Т., Манн, Дж. Л., Сильвер, Т., Тененбаум, Дж. Б., и Мансингка, В. К. (2020). Онлайн-байесовский вывод цели для ограниченно-рациональных агентов планирования. Доп. Нейронная инф.Обработать. Сист. 33.
Google Scholar
Для начинающих: через лабиринт с роботом Finch
Примечание для учителя
Для этого задания ваши ученики могут запрограммировать Finch с помощью Snap! Уровень 1 с использованием ноутбуков или Chromebook. Щелчок! Уровень 1 — это очень простой язык программирования, и учащимся не требуется предварительный опыт программирования. Чтобы установить и начать использовать Snap! на ноутбуке или Chromebook ознакомьтесь с этим руководством.
Для этого задания учащиеся должны построить для робота небольшой лабиринт. Они могут построить лабиринт из картона (рисунок ниже) или наметить маршрут с помощью скотча или стаканчиков/конусов. Каждой группе учащихся также понадобится секундомер.
Они могут построить лабиринт из картона (рисунок ниже) или наметить маршрут с помощью скотча или стаканчиков/конусов. Каждой группе учащихся также понадобится секундомер.
Перемещение зяблика
Используйте USB-кабель для подключения Finch к компьютеру. Чтобы Finch запускал программу, этот шнур всегда должен быть подключен к роботу и к компьютеру.
Начните с открытия сервера роботов Birdbrain (если вы используете ноутбук) или приложения Finch Connection (если вы используете Chromebook).Он должен показать, что ваш Finch подключен. Затем выберите Snap! Уровень 1 и откройте программу.
Посмотрите это видео, чтобы узнать, как использовать Snap! Уровень 1, чтобы заставить Зяблика двигаться и поворачиваться.
Четыре блока со стрелками перемещают Зяблика. Стрелка вверх перемещает зяблика вперед на одну секунду. Стрелка вниз перемещает зяблика назад на одну секунду. Стрелки влево и вправо поворачивают Зяблика влево и вправо.
Начиная с блока при нажатии клавиши, попробуйте создать программу, используя шесть блоков со стрелками. Как вы думаете, как будет двигаться зяблик, когда вы запустите программу?
Как вы думаете, как будет двигаться зяблик, когда вы запустите программу?
Совет: Возможно, вам придется носить с собой USB-кабель, когда Finch перемещается. В противном случае шнур может препятствовать свободному движению и вращению Finch.
Через лабиринт
Теперь, когда вы знаете, как заставить Зяблика двигаться, вы можете помочь ему пройти через лабиринт. При настройке лабиринта добавьте несколько поворотов, чтобы сделать его более сложным! Чтобы создать свой лабиринт, вы можете использовать картонные коробки, скотч или стаканчики/конусы.На рисунке ниже показан образец картонного лабиринта, созданного преподавателями программы Института обучения с помощью технологий и инновационных практик (ITTIP) Университета Лонгвуда.
Сначала вы напишете скрипты, которые позволят вам управлять роботом дистанционно. Например, вы хотите, чтобы робот двигался вперед, когда вы нажимаете стрелку вверх. При написании сценариев подумайте о том, какие движения нужно будет совершать Зяблику. Какие клавиши вы можете использовать для управления Finch?
Какие клавиши вы можете использовать для управления Finch?
Совет: Вы можете использовать блок при нажатии клавиши , чтобы заставить Зяблика двигаться по-разному.Этот блок находится в меню Control . Когда вы добавляете блок при нажатии клавиши , он автоматически говорит «при нажатии клавиши пробела». Вы можете щелкнуть стрелку раскрывающегося списка, чтобы выбрать, какую клавишу вы хотите использовать. Например, на картинке ниже показана программа, которая заставит зяблика двигаться при нажатии клавиши «а».
Когда вы закончите свои сценарии, используйте их, чтобы провести робота через лабиринт. Используйте секундомер, чтобы измерить, сколько времени потребуется роботу, чтобы пройти лабиринт.Запишите этот номер, он понадобится вам позже.
Затем напишите программу, позволяющую роботу самостоятельно проходить лабиринт. Это означает, что робот должен двигаться по лабиринту самостоятельно. Вы можете нажать клавишу, чтобы запустить скрипт, но после этого вы не можете использовать клавиатуру или перемещать робота. Не забывайте часто тестировать свою программу, добавляя в нее блоки. Кроме того, чаще сохраняйте свою работу!
Вы можете нажать клавишу, чтобы запустить скрипт, но после этого вы не можете использовать клавиатуру или перемещать робота. Не забывайте часто тестировать свою программу, добавляя в нее блоки. Кроме того, чаще сохраняйте свою работу!
Когда вы закончите вторую программу, используйте секундомер, чтобы измерить, сколько времени потребуется роботу, чтобы самостоятельно пройти лабиринт.Если у вас есть время, постарайтесь, чтобы робот прошел лабиринт как можно быстрее.
Сравните эти два способа прохождения лабиринта. Что быстрее, дистанционное управление или автономность? Что лучше подойдет для нового лабиринта?
Расширение
Попробуйте использовать Snap! Уровень 2 или Snap! Уровень 3 – написать программу для прохождения лабиринта. Можете ли вы пройти лабиринт быстрее?
(PDF) Автономный робот для решения лабиринтов *
Автономный робот для решения лабиринтов
*
Rares Covaci
Технический университет Клуж-Напока
Департамент автоматизации
Клуж-Напока, Румыния
Клуж-Напока, Румыния
COM
Gabriel Harja
Технический университет CLUJ Napoca
Отдел автоматизации
Cluj Napoca, Румыния
Gabriel. harja@aut.utcluj.ro
harja@aut.utcluj.ro
IOAN NAZCU
Технический университет Cluj Napoca
Отдел автоматизации
Клуж-Напока, Румыния
Ioan.Nascu@aut.utcluj.ro
В этой статье будет представлена конструкция и программирование
робота для решения лабиринтов.В начале
предлагается общий обзор, за которым следуют основные технические аспекты
и детали реализации. Основная задача робота
— разведка и картографирование местности. Однако после завершения процесса исследования
часто требуется, чтобы робот
мог найти конкретный объект или вернуться в заданную точку.
Предлагаемая местность представляет собой лабиринт, состоящий из линий,
поворотов иперекрестков, которые робот обнаруживает с помощью инфракрасных датчиков.Алгоритм
для исследования, изучения и решения
лабиринта был реализован. Поэтому роботу удается оптимально найти
выход из лабиринта во время второго прогона. Модуль Bluetooth
использовался для передачи данных в режиме реального времени и отображения их в Matlab
во время работы робота.
Ключевые слова: автономный робот, решение лабиринтов, управление, PI
I. ВВЕДЕНИЕ
Мобильные роботы представляют собой постоянно развивающуюся технологию, и
имеют большое значение в научных и промышленных областях, поскольку их способность решать сложные задачи постоянно развивались.Существует широкий спектр приложений, в которых используются мобильные роботы
: исследование труднопроходимой местности, наблюдение
и обеспечение безопасности [1], хозяйственная деятельность (уборка помещений), военное применение (обнаружение наземных мин), транспорт. (nu-
уборка отходов), спасательные операции и даже исследование космоса
. Однако возможность выполнения этих задач
идет рука об руку с рядом требований: мобильный робот
должен работать безопасно, как для собственной безопасности, так и для окружающей среды
[2] (не нанося ущерба окружающей среде или окружающей среде).
представляющие опасность для живых существ). Более того, учитывая ограниченное
пространство для перемещения, мобильность становится важным фактором, поскольку выполнение необходимых движений в заданных границах
пространства часто оказывается существенным. Наконец, способность работать самостоятельно является основным требованием для автономных роботов, поскольку они должны уметь находить направления и достигать определенных целей, основываясь только на своих датчиках и алгоритмах, реализованных в программном обеспечении.
Точность является ключевой концепцией мобильных роботов.Ожидаемая точность
может быть достигнута только при использовании специальных алгоритмов управления
, которые удерживают движения робота в предписанных
ограничениях. На протяжении десятилетий ПИД-регулятор был наиболее
распространенным алгоритмом управления из-за его очевидных преимуществ: он имеет простую и понятную структуру, а также подходит для
большинства контуров управления. К.Дж. Астром утверждает в одной из своих статей [3]
, что ПИД-регуляторы используются более чем в 90% контуров управления
в промышленных приложениях.
Работа организована следующим образом: описание автономного робота
представлено в следующем разделе. Раздел III
описывает методы контроля, которые использовались в этой работе. Оптимизация пути, результаты моделирования управления с замкнутым контуром
и сравнение двух алгоритмов управления
включены в раздел IV, а последний раздел
обобщает выводы.
II. ROB OT CONSTRUCTION
Что касается конструкции робота, то были учтены некоторые аспекты
.Прежде всего, лабиринт и робот должны быть
соответствующих размеров. Кроме того, робот должен уметь
бегать по лабиринту, поворачиваться и сменяться, если
нужно. В качестве переднего колеса был выбран шариковый ролик
, чтобы обеспечить большую мобильность. Размещение дополнительной платформы над шасси
также помогает уменьшить размер робота. Аккумулятор
был размещен на нижней платформе для повышения устойчивости.
Окончательный вариант робота показан на рис. 1.
1.
Использовались следующие аппаратные компоненты:
• Плата разработки STM32F303RE;
Рис. 1. Обзор конструкции робота. Загружено 13 мая 2021 г. в 04:31:19 UTC с сайта IEEE Xplore. Ограничения применяются.
目黒将司 (Shoji Meguro) – Autonomy Lyrics
Autonomy Lyrics
Verse 1Плотно – стены смыкаются вокруг меня
Как жестокий сон
Белое, серое, черное и каштановое
Лабиринт крутых поворотов Дикое множество
Куплет 2
Небо – я вижу часть его, глядя прямо вверх
Надо подняться
Ярко-голубой квадрат солнечного света
Кусочек хорошей жизни
Так далеко
Пре-Припев
Кто говорит что я не могу достичь этого квадрата неба
Что я не могу подняться
Хор
В небо
Поднимись высоко
Автономность
Почти в пределах моей досягаемости
Поднимись высоко
Возьми мое небо
Моя истинная целостность
Сломай лабиринт игры мы
Играй – я ничего не могу сделать, кроме как играть сейчас
Должен вступить сейчас
Играй – и победа, единственный выход
Сюжет должен разыграться
До конца
Стих 4
Игры – общество постоянно меняется
Правила и правила
Игры – не все ли мы занимаемся
Некоторые игры мы устраиваем
С соперниками и друзьями?
[Интерлюдия]
Куплет 5
Моря — я иногда вижу их вдалеке
Я слушаю
Пожалуйста — кто-нибудь там слышит меня
Моя надежда плыть на свободе
За пределами игры?
Куплет 6
Сердце в тисках но как-то вырвалось
Я проснулась и нашла (могу)
Начинаю наконец схватывать закономерность
Еще один крутой поворот
По пути
Я знаю что могу Найди мой путь к ветру
И открытым водам
Хор
Ставь паруса
Я не могу потерпеть неудачу
Автономия
Теперь почти в пределах досягаемости
Храбрые моря
Найди мой покой
Мне нужно только пробить
Эти старые стены, сломай Все они повержены
Стих 7
Удары — сыплются на мою голову, как град, сейчас
Должен спастись сейчас
Выбрал победу, мое единственное правило —
Мой единственный ход —
Остаться на вершине
Стих 8
Завесы, которые скрывают программу, управляющую выходом из лабиринта
Под моим взглядом
Сказки растут, когда я иду быстрее
На встречу с моим хозяином
И я не остановлюсь
Мост
Кто-нибудь верит, что я могу победить?
Рядом со мной
Кто действительно на моей стороне?
Только я сам и я, эта команда
Становится сильным и диким
Со временем
Хор
Поднимись высоко
Чувство дикой природы
Автономия
Сейчас почти в пределах досягаемости Храбрый
Любая волна
Автономия
Сейчас почти в пределах досягаемости
Небо и море
Освободи меня
Мне нужно только прорваться
Эти старые стены, сломай их всех
Стих 9
Любовь – жить моя единственная цель чтобы выжить
Должен остаться в живых
Что ты собираешься сделать, чтобы остановить меня?
Никто не может остановить меня
Я в ударе
Куплет 10
Прячься — лучше постарайся держаться подальше от меня
Я уже в пути
Autonomy now
Автономный агент — обзор
1 Введение
Чтобы автономный агент мог работать в реальной среде, он должен решить как минимум три основные проблемы. Во-первых, чтобы позволить агенту работать в режиме реального времени, он должен иметь возможность реагировать на события с той скоростью, с которой они происходят. Во-вторых, поскольку события реального мира обычно не имеют предопределенного начала, середины или окончания, агент должен иметь возможность формировать свои собственные сегменты. И, наконец, поскольку часто нет внешнего учителя, который бы руководил им, агент должен иметь возможность изучать свои категории без присмотра. В этой главе будут рассмотрены эти и другие вопросы. Он попытается разработать нейронную сеть в реальном времени, которая учится сегментировать бесконечный поток входных данных без присмотра. 2
Во-первых, чтобы позволить агенту работать в режиме реального времени, он должен иметь возможность реагировать на события с той скоростью, с которой они происходят. Во-вторых, поскольку события реального мира обычно не имеют предопределенного начала, середины или окончания, агент должен иметь возможность формировать свои собственные сегменты. И, наконец, поскольку часто нет внешнего учителя, который бы руководил им, агент должен иметь возможность изучать свои категории без присмотра. В этой главе будут рассмотрены эти и другие вопросы. Он попытается разработать нейронную сеть в реальном времени, которая учится сегментировать бесконечный поток входных данных без присмотра. 2
Способность сегментировать паттерны в реальном времени важна в таких областях, как распознавание объектов, обучение с подкреплением и распознавание речи. Рассмотрим распознавание речи. Во-первых, поскольку язык интерактивен, необходима работа в режиме реального времени. Во-вторых, как может подтвердить любой, кто когда-либо слушал незнакомый иностранный язык, между словами предложения редко бывают четкие границы. Таким образом, умение формировать сегментации при наличии посторонней информации также является обязательным.И в-третьих, если мы хотим моделировать людей, наши системы должны иметь возможность изучать язык без присмотра. Это понятно, так как младенцы учат свой родной язык, просто слушая его.
Таким образом, умение формировать сегментации при наличии посторонней информации также является обязательным.И в-третьих, если мы хотим моделировать людей, наши системы должны иметь возможность изучать язык без присмотра. Это понятно, так как младенцы учат свой родной язык, просто слушая его.
Очевидно, что создание нейронных сетей, способных обучаться непрерывной речи, все еще выходит за рамки современных технологий. Однако, рассматривая упрощенную версию проблемы, можно смоделировать непрерывный характер речи в реальном времени без чрезмерного усложнения проблемы.После того, как упрощенная задача решена, можно заняться дополнительными вопросами.
Таким образом, входные шаблоны не будут состоять из непрерывных речевых сигналов. Вместо этого они будут состоять из бесконечных последовательностей элементов. Для удобства элементы будут представлены заглавными буквами. Однако также можно думать об элементах как о фонемах, числах, музыкальных нотах и т. д. Эти элементы будут последовательно представлены в сеть с постоянной скоростью и интенсивностью. Затем задача нейронной сети будет заключаться в том, чтобы научиться сегментировать входные последовательности, обнаруживая заложенные в них значимые закономерности.
Затем задача нейронной сети будет заключаться в том, чтобы научиться сегментировать входные последовательности, обнаруживая заложенные в них значимые закономерности.
Например, рассмотрим приведенную ниже последовательность, которая многократно представлена в сети. Письма предъявляются по одному, без перерывов в изложении. Следовательно, после того, как представлена последняя буква Z , сразу же снова представлена первая буква в последовательности E, . Обратите внимание, что списки EAT и NOW встроены в несколько разных мест (контекстов). Из-за этого сеть должна научиться распознавать EAT и NOW как значимые шаблоны.
+ +| Е | Т | В | с | D | Н | О | Вт | F | G | Н | Я | |||
| Е | Т | J | К | L | М | Н | О | Вт | Р | В | R | |||
| Е | Т | С | У | В | Н 9 0122 | O | W | x | 9 | Z |
Если сеть рассматривается как черный ящик, она может быть изображена как на рисунке 1 Каждая входная строка представляет дискретное событие или элемент. Элемент представляется сети путем кратковременной активации его строки ввода, а список представляется путем последовательного представления различных элементов. На рис. 2 показана активация входных линий, когда в сети представлены списки ABC, и CAB.
Элемент представляется сети путем кратковременной активации его строки ввода, а список представляется путем последовательного представления различных элементов. На рис. 2 показана активация входных линий, когда в сети представлены списки ABC, и CAB.
Рисунок 1. Черный ящик сети.
Рис. 2. (а) Последовательная активация строк ввода при предъявлении списка ABC. (b) Активация линий ввода при представлении CAB .
Перепечатано с разрешения Нигрина (1993).В этой главе введено несколько ограничений на типы разрешенных входных данных. Методы преодоления этих ограничений обсуждаются в Nigrin (1990, 1993).
- 1.
Ни один элемент не может повторяться в одном списке. Например, список ABC может быть представлен в сети, а список ABA — нет. Это ограничение наложено по двум причинам. Во-первых, в текущей модели существует только одно место хранения для каждого отдельного элемента, а во-вторых, в настоящее время неизвестно, как использовать один узел для однозначного представления нескольких вхождений элемента.
Следовательно, прежде чем элемент можно будет повторить, необходимо сбросить активность в месте его хранения.- 2.
Элементы представляются путем активации линий ввода с фиксированной интенсивностью в течение фиксированных периодов времени. Таким образом, единственной важной информацией, которую можно изменить, является последовательность элементов. В этой главе не рассматривается возможность различных ритмов или разной интенсивности представления предметов.
- 3.
Для простоты во время любого моделирования не присутствует шум, и элементы не искажаются.Однако сеть была протестирована на зашумленных паттернах при моделировании статических пространственных паттернов (Нигрин, 1993).
 Следовательно, прежде чем элемент можно будет повторить, необходимо сбросить активность в месте его хранения.
Следовательно, прежде чем элемент можно будет повторить, необходимо сбросить активность в месте его хранения. Мы решим эту проблему, используя самоорганизующуюся нейронную сеть под названием SONNET 1. SONNET 1 разделен на два отдельных поля единиц: F (1) и F (2) , как показано на рис. Рисунок 3. F (1) содержит узлы, представляющие различные элементы ввода, которые могут быть представлены в сети.Каждый узел представляет конкретный элемент (или событие) и получает внешние входные данные от одной входной строки, которая представляет элемент. F (1) преобразует последовательную активацию различных входных линий в пространственный паттерн активности в кратковременной памяти (STM) для представления последовательности элементов. F (1) узлов представляют последовательный порядок, поэтому они будут обозначаться буквой s. И название, и деятельность i -й ячейки в F (1) задается как s i .
F (1) содержит узлы, представляющие различные элементы ввода, которые могут быть представлены в сети.Каждый узел представляет конкретный элемент (или событие) и получает внешние входные данные от одной входной строки, которая представляет элемент. F (1) преобразует последовательную активацию различных входных линий в пространственный паттерн активности в кратковременной памяти (STM) для представления последовательности элементов. F (1) узлов представляют последовательный порядок, поэтому они будут обозначаться буквой s. И название, и деятельность i -й ячейки в F (1) задается как s i .
Рисунок 3. Структура сети в этой главе. F (1) преобразует временные последовательности событий в пространственные паттерны активности. F (2) классифицирует эти развивающиеся пространственные паттерны.
Перепечатано с разрешения Нигрина (1993).
F (2) имеет наборы ячеек, представляющие списки элементов. Чтобы быть более точным, F (2) учится распределять эволюционирующие пространственные паттерны активности по F (1) .И название, и активность сборки и -й клетки в даются формулой x i .
Используя описанную выше архитектуру, необходимо решить три основные проблемы. Во-первых, необходимо найти ограничения, управляющие преобразованием временных событий в пространственный паттерн деятельности. Во-вторых, после разработки адекватного преобразования необходимо разработать механизмы нейронной сети по телефону F (1) для реализации этого преобразования.И в-третьих, сети должны быть спроектированы по адресу F (2) , которые могут классифицировать эти несегментированные пространственные паттерны в режиме реального времени.
Глава организована следующим образом. В разделе 2 обсуждается общий способ классификации шаблонов по номеру F (2) . Затем в разделах с 3 по 5 будут обсуждаться различные ограничения на преобразование последовательности временных событий в пространственные паттерны деятельности. В разделах 6 и 7 обсуждаются конкретные архитектуры, с помощью которых это можно реализовать.В разделе 8 обсуждаются свойства, которыми должна обладать система классификации, чтобы она могла классифицировать преобразованные шаблоны. В разделе 9 будет представлено небольшое количество симуляций, чтобы показать, что эта схема правдоподобна, а в разделе 10 представлено дополнительное обсуждение.
Затем в разделах с 3 по 5 будут обсуждаться различные ограничения на преобразование последовательности временных событий в пространственные паттерны деятельности. В разделах 6 и 7 обсуждаются конкретные архитектуры, с помощью которых это можно реализовать.В разделе 8 обсуждаются свойства, которыми должна обладать система классификации, чтобы она могла классифицировать преобразованные шаблоны. В разделе 9 будет представлено небольшое количество симуляций, чтобы показать, что эта схема правдоподобна, а в разделе 10 представлено дополнительное обсуждение.
Почему изучение кукурузного лабиринта должно стоять на первом месте в списке ваших семейных занятий
Parenting Today Представлено Департаментом образования и дошкольного образования Сиэтла
По мере того, как осенние семейные мероприятия начинают заполнять ваш социальный календарь, подумайте об одном из самых популярных — кукурузном лабиринте! Выйти на поле и весело провести время, преодолевая повороты и повороты, — это отличный способ провести день со своими детьми, но знаете ли вы, что помимо удовольствия есть и другие преимущества?
Вот лишь несколько причин, по которым прогулки с детьми по кукурузному лабиринту могут превратить вашу семейную забаву в реальную пользу для развития ваших детей.
Дайте своим детям шанс потерпеть неудачу, а затем добиться успеха
Любой, кто прошел через кукурузный лабиринт, знает, что риск неудачи на этом пути высок — вы обязательно сделаете хотя бы один неверный поворот! Хотите верьте, хотите нет, но занятие со встроенными шансами на неудачу — отличный способ помочь вашим детям привыкнуть к идее неудачи, попытки снова и, в конечном итоге, успеха. В эпоху, когда многим детям не дают возможности практиковать устойчивость перед лицом неудач, для родителей важнее, чем когда-либо, находить возможности, чтобы их дети преодолевали препятствия.Джессика Лахи, автор книги «Дар неудачи », повторяет эту идею в своем описании основной цели современных родителей:
. «Какая практика воспитания может помочь нашим детям приобрести навыки, ценности и добродетели, на которых строится позитивное чувство собственного достоинства? Воспитание автономии. Воспитание независимости и чувства собственного достоинства, основанное на реальной компетентности, а не ошибочной уверенности. Воспитание стойкости перед лицом ошибок и неудач».
Воспитание стойкости перед лицом ошибок и неудач».
Когда семьи вместе сталкиваются с неудачами, родители и старшие дети показывают младшим детям стойкость и настойчивость.Когда мама сворачивает не в ту сторону и не позволяет своему разочарованию и досаде положить конец занятиям, дети могут научиться аналогичным образом превращать свои неудачи в успехи. Чтобы максимально использовать эту возможность, пусть ваши дети сами пройдут через лабиринт. Комментируйте как можно нейтральнее, когда они неизбежно ошибаются, и присоединяйтесь к их чувству выполненного долга, когда они доходят до конца!
Улучшение пространственного восприятия и навыков ориентации
Мы все знаем взрослых (может быть, даже самих себя!), которые плохо ориентируются в направлениях вроде восток и юг , но пространственное и ориентированное понимание — это навыки, которые выходят далеко за рамки способности «направиться на север на 5 миль.«Понимание того, где находится ваше тело по отношению к пространству вокруг него, и знание того, как использовать свои мышцы для навигации в этом пространстве, — это навыки, которые профессионалы называют пространственным восприятием и проприоцепцией. Эти навыки имеют решающее значение для навигации по местоположению, передвижению, личному пространству, чтению и письму, а также математике.
Эти навыки имеют решающее значение для навигации по местоположению, передвижению, личному пространству, чтению и письму, а также математике.
Лучший способ помочь детям улучшить пространственное мышление и навыки ориентирования — это игра! Когда вы направляетесь в кукурузный лабиринт, используйте возможность, чтобы ваши дети блуждали и исследовали то, что они считают нужным, а затем добавьте некоторые идеи направления, чтобы бросить им вызов, например: «Как насчет того, чтобы мы повернули налево еще примерно через две длины тела». ?» Кроме того, весь опыт кукурузного лабиринта развивает эти пространственные навыки.Так что, если ваш малыш ударится головой о стену из кукурузы, не переживайте; просто помните, что они все еще тренируют свою проприоцепцию и пространственное восприятие!
Сделайте движение веселым
Физическая активность и движение имеют решающее значение для детей всех возрастов, поэтому очень важно найти способы сделать движение веселым и естественным. Выходить на улицу и проводить время с семьей, занимаясь физическими упражнениями, — это отличный способ показать детям, что движение тела доставляет удовольствие и является приоритетом для вашей семьи.Не отказывайтесь от творческого подхода, перемещаясь по кукурузному лабиринту — вы можете включить множество забавных подвижных игр, которые помогут укрепить мышцы и кости и обеспечить некоторую аэробную активность. Например, пусть ваши дети прыгают, как кролики, вниз по одному ряду, а затем идут крабом вверх по другому, или устройте гонку среди детей постарше, чтобы увидеть, кто быстрее добежит к выходу.
Выходить на улицу и проводить время с семьей, занимаясь физическими упражнениями, — это отличный способ показать детям, что движение тела доставляет удовольствие и является приоритетом для вашей семьи.Не отказывайтесь от творческого подхода, перемещаясь по кукурузному лабиринту — вы можете включить множество забавных подвижных игр, которые помогут укрепить мышцы и кости и обеспечить некоторую аэробную активность. Например, пусть ваши дети прыгают, как кролики, вниз по одному ряду, а затем идут крабом вверх по другому, или устройте гонку среди детей постарше, чтобы увидеть, кто быстрее добежит к выходу.
Делитесь смехом, успехом и дружбой
Одной из главных причин провести время в кукурузном лабиринте вместе всей семьей является общая связь, которая у вас разовьется в процессе.Смеяться над спонтанными шутками, вместе праздновать достижение цели и рассказывать о своем путешествии — все это способы укрепить связь в вашей семье. Эта связь, в свою очередь, может помочь детям научиться ориентироваться в социальных ситуациях, улучшить успеваемость и поощрять лучшее поведение.
Отправляясь в кукурузный лабиринт в этом сезоне, не забудьте дать своим детям возможность укрепить навыки в процессе. Прежде всего, расслабьтесь, получайте удовольствие и наслаждайтесь смехом!
Parenting Today представляет Программу помощи по уходу за детьми (CCAP) Департамента образования и дошкольного образования Сиэтла.Программа помощи по уходу за детьми (CCAP) обслуживает детей в возрасте от 0 до 12 лет в более чем 200 поставщиках услуг по всему городу. Узнайте больше: ccap@seattle.gov или позвоните по телефону (206) 386-1050.
.