Развал схождение всё что нужно знать
Сход и развал колес автомобиля по отношению друг к другу — это два разных параметра подвески, у которых одинаковая цель регулировки, заключающаяся в улучшении ходовых качеств машины. Основная цель регулировки этих параметров заключается в правильной установке колес таким образом, чтобы верхние и нижние их части были симметричны.
Как делается развал схождение
Добиться абсолютной параллельности подручными средствами не получится, потому что делается развал схождение следующим образом:
-
схождение делается путем регулирования угла между плоскостью вращения колесного диска и продольной осью транспорта. Чем точнее настроен этот параметр, тем выше прямолинейность движения;
-
развал регулируется за счет настройки угла, под которым по отношению к дороге в вертикальной плоскости расположены колеса.
Допускаются небольшие отклонения колес наружу или внутрь, но даже их сложно выдержать подручными средствами. Поэтому для решения этой задачи нужно обращаться в автосервисы, где имеются стенды развал-схождение и опытные специалисты. Так как современные стенды оснащены компьютером под управлением операционной системы, программное обеспечение, считывая информацию с датчиков, безошибочно определит состояние развал-схождения. Это позволяет добиться максимально точной регулировки положения колес.
Поэтому для решения этой задачи нужно обращаться в автосервисы, где имеются стенды развал-схождение и опытные специалисты. Так как современные стенды оснащены компьютером под управлением операционной системы, программное обеспечение, считывая информацию с датчиков, безошибочно определит состояние развал-схождения. Это позволяет добиться максимально точной регулировки положения колес.
Технические нюансы регулировки
Регулировка данного параметра способствует повышению уровня безопасности автомобиля, так как при симметричном расположении колес по отношению друг к другу улучшается управление машиной и ее устойчивость на дороге. Это гарантирует снижение вероятности заноса на поворотах, экономию топлива и увеличение эксплуатационного срока автопокрышек за счет медленного износа. В противном случае протектор автопокрышек изнашивается неравномерно. Возникающие дополнительные нагрузки на колеса приводят к большему потреблению мощности двигателя и, как следствие, увеличенному расходу топлива. Следовательно, проверять соответствие данных параметров норме необходимо регулярно, так как ввиду получаемых ходовой частью нагрузок постепенно значения отклоняются от нормы.
Следовательно, проверять соответствие данных параметров норме необходимо регулярно, так как ввиду получаемых ходовой частью нагрузок постепенно значения отклоняются от нормы.
Как проверить развал схождение
Чтобы проверить развал схождение на соответствие нормам, достаточно загнать авто на регулировочный стенд и провести диагностику. Но чтобы не обращаться каждый раз в автосервис, можно самостоятельно узнать требуется ли такая регулировка или колеса стоят симметрично. Для этого достаточно обычной телескопической линейки. С ее помощью измеряется расстояние между нижней частью колес и верхней. Если значение нижней части меньше верхнего, то определенно колеса имеют развал по отношению друг к другу. Если нижнее значение больше верхнего, это говорит о схождении колес. В обоих случаях необходимо отрегулировать колеса до полной симметричности.
Сколько по времени делать развал схождения
Как отмечают специалисты автосервиса, по времени регулировать развал схождение в среднем приходится около 40 минут.
Что учитывается при регулировке
Чтобы понять, как выполняется регулировка развала схождения, нужно знать несколько терминов и определений.
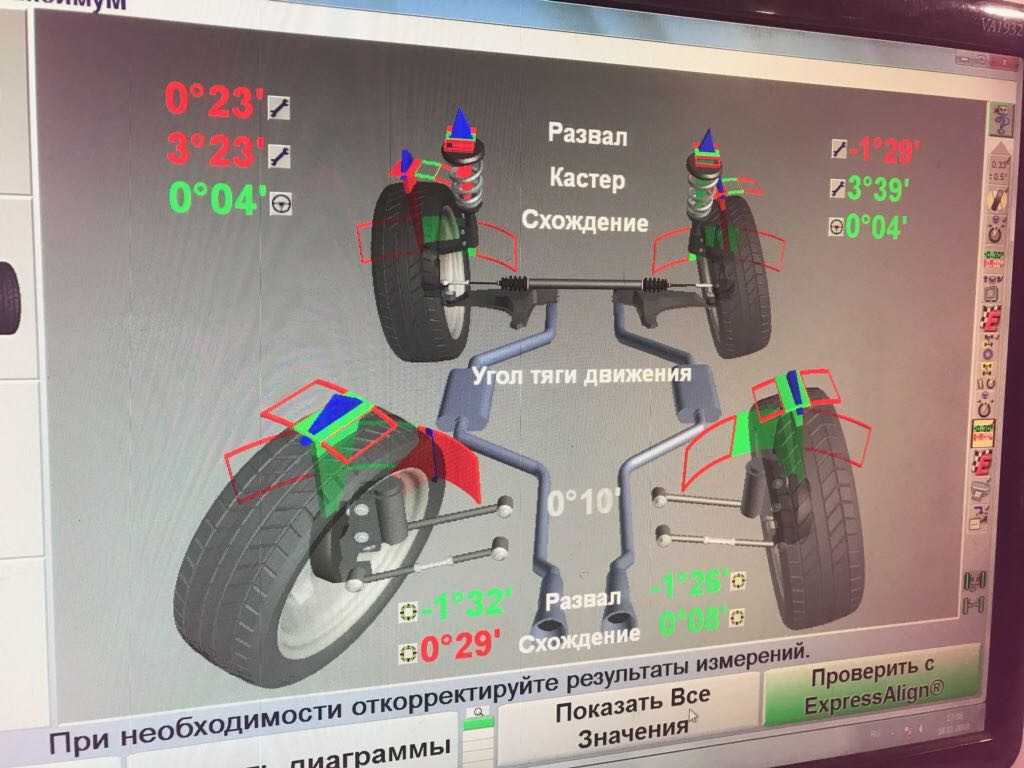
Такое понятие, как Кастер колеса — не что иное, как угол под которым расположена его поворотная ось по отношению к вертикали. Также существует отдельное понятие — кастер передней подвески. Он способствует прогрессивному наклону колес, установленных на передней оси туда, куда они поворачивают. Кроме того, этот угол учитывают еще и при диагностике наката, торможения и ускорения, определяя его влияние на эти факторы.
Важное значение при регулировке развал схождения имеет угол Аккермана. Оптимальный угол определяется по принципу Аккермана, с помощью которого можно выяснить идеальную геометрию рулевого управления. При установке корректного угла Аккермана, автомобиль становится более устойчивым при входе в повороты или движении по кривой.
Оптимальный угол определяется по принципу Аккермана, с помощью которого можно выяснить идеальную геометрию рулевого управления. При установке корректного угла Аккермана, автомобиль становится более устойчивым при входе в повороты или движении по кривой.
Сколько времени занимает регулировка развала-схождения? И когда нужно ее делать?
Регулировка углов установки колес, или регулировка развала-схождения, занимает около часа, если в подвеске нет поломок. Если у автомобиля есть проблемы с регулировочными болтами и элементами подвески, процедура может занять до двух часов.
Регулировка углов установки колес — крайне необходимая процедура, которая позволит вам продлить срок службы шин, обеспечить оптимальное торможение, комфортную поездку и повысить безопасность на трассе. Регулировать развал-схождение следует каждые 2 или 3 года или каждый раз, когда вы ремонтируете подвеску и систему рулевого управления вашего автомобиля.
Что же подразумевает регулировка развала-схождения?
Регулировка развала-схождения — это процесс выравнивания колес и шин относительно поверхности дороги и относительно положения других колес.
По сути, это регулировка подвески автомобиля таким образом, чтобы шины касались земли всей своей рабочей поверхностью. Это обеспечивает оптимальное сцепление с асфальтом и лучшую устойчивость на дороге.
Что такое развал, схождение и кастер?
Стоит понимать, что регулировка углов установки колес — это в основном корректировки, которые касаются трех основных факторов — развала, схождения и кастера.
Развал — это уклон колеса внутрь или наружу, если смотреть спереди автомобиля. В некоторых спортивных автомобилях оптимальный развал может быть отрицательным — это обеспечивает лучшую устойчивость авто на дороге. Но для продления срока службы шин оптимальным углом развала является центральная осевая линия.
Схождение — это уклон колеса внутрь или наружу, если смотреть сверху на автомобиль. Неправильные углы схождения — основная проблема, которые может увеличить расход топлива, повлиять на рулевое управление и вызвать другие проблемы. Угол схождения всегда должен соответствовать центральному положению.
Кастер (Caster) — это еще один угол, который показывает положение оси рулевого управления при взгляде сбоку от транспортного средства. Неправильный уклон приводит к неточному рулевому управлению и плохой устойчивости.
Сколько занимает развал-схождение? Считаем
- Техник проверяет давление в шинах — 3 минуты.
- Автомобиль ставится на специальный подъемник с измерительными инструментами — 2 минуты.
- Измерительное оборудование устанавливается на каждое колесо — 10 минут.
- Происходят проверки, компьютер регистрирует схождение, развал и кастер — 3 минуты.
- Мастер выравнивает колеса с помощью специальных болтов и гаек — 20 минут.
- Проверки повторяются с анализом новых углов — 3 минуты.
- Техник затягивает все болты и гайки, которыми он регулировал колеса — 10 минут.
- Вы получаете инструкции, а также отчет о проделанной работе — 2 минуты.
- Вы платите деньги за услугу и покидаете СТО — 3 минуты.


Как часто нужно проверять углы развала-схождения?
Лучше всего следовать рекомендациям производителя автомобиля. Однако большинство мастеров согласны с тем, что регулировка колес потребуется каждые 2 или 3 года.
Есть несколько ситуаций, когда настоятельно рекомендуется регулировка углов установки колес:
- отремонтирована система рулевого управления;
- отремонтирована подвеска;
- куплены новые шины;
- вы попали в большую яму на дороге.
В этих случаях углы установки колес могут сместится, и вам нужно будет это проверить.
Также есть признаки того, что ваш автомобиль требует процедуры регулировки колес:
- неравномерный износ шин, который можно увидеть, глядя на рабочую поверхность шины;
- автомобиль тянет в сторону при движении;
- положение руля смещенное — руль немного повернут влево или вправо, но машина продолжает ехать прямо;
- рулевое колесо вибрирует, особенно при достижении скорости 100-110 км/ч.

Это серьезные признаки, которые говорят о том, что вашему автомобилю необходимо как можно скорее выполнить регулировку развала-схождения.
Что мне нужно: регулировка углов установки колес или балансировка?
Балансировка колес необходима, когда одно колесо вращается нестабильно. На скорости до 60 км/ч проблем не будет, но затем машина может начать трястись, ее может немного тянуть в сторону. Симптомы очень похожи на проблемы с регулировкой углов развала-схождения.
Вы можете начать с того, что дешевле. Обычно дешевле и быстрее проверять балансировку колес, а затем, если все в порядке, можно заказать регулировку углов установки колес.
Могу ли я самостоятельно выровнять развал-схождение?
К сожалению, это совершенно невозможно. Углы схождения и развала трудно зарегистрировать без точного компьютерного оборудования. Кроме того, вам нужно будет знать, где находятся болты для выравнивания, и как их использовать. Безопаснее и проще пользоваться для этого услугами специальных СТО.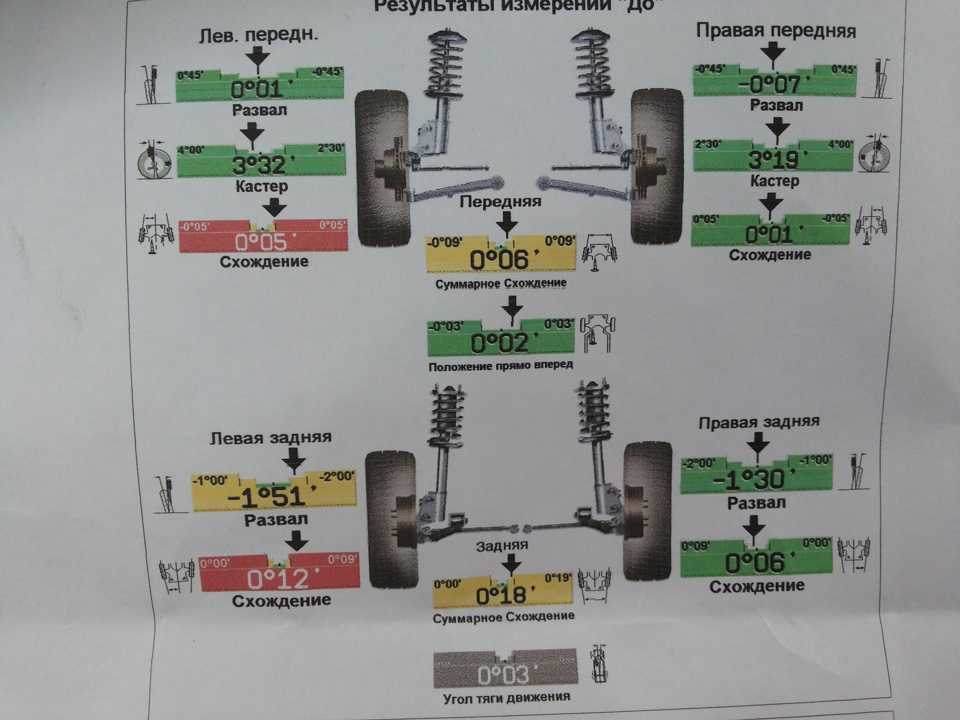
Что делать, если мне не нужна регулировка углов установки колес?
Если вы не хотите платить за регулировку углов установки колес, вам, вероятно, придется чаще покупать новые шины. Кроме того, вам придется мириться с плохим рулевым управлением и слабым уровнем безопасностью при вождении автомобиля. Лучше найдите самое дешевое предложение в вашем городе и отрегулируйте колеса. Но обратите внимание, что углы схождения и развала можно правильно выровнять только с помощью профессионального оборудования. Так что убедитесь, что такая техника есть на выбранной вами СТО.
Понравился этот контент? Подпишитесь на обновления!
Как сделать развал схождение самому с высокой долей точности?
После Удара Колеса Смотрят в Разные Стороны – Что Произошло с Автомобилем?
Присутствует вибрация при разгоне: главные причины неполадки
Машина трясется при разгоне – в чем может быть проблема?
Вибрация на скорости 120-140 км/ч – что это может быть?
К списку статей
Социальные комментарии Cackle
Режимы отказаGAN: как их идентифицировать и контролировать
Генеративно-состязательная сеть представляет собой комбинацию двух подсетей, которые конкурируют друг с другом во время обучения, чтобы генерировать реалистичные данные.
Хотя GAN являются мощными моделями, их довольно сложно обучить. Мы обучаем Генератор и Дискриминатор одновременно, за счет друг друга. Это динамическая система, в которой, как только параметры одной модели обновляются, меняется характер задачи оптимизации, и из-за этого достижение сходимости может быть затруднено.
Обучение также может привести к сбою GAN при моделировании полного распределения, и это также называется Сбой режима .
В этой статье:
- мы увидим, как обучить стабильную модель GAN
- , а затем поэкспериментируем с процессом обучения, чтобы понять возможные причины сбоев режима.
Я тренировал GAN в течение последних нескольких лет и заметил, что обычные режимы отказа в GAN — Mode Collapse и Convergence Failure , о которых мы поговорим в этой статье.
Пропустите раздел обучения и перейдите к разделу режимов отказа ->
Обучение стабильной сети GAN
Чтобы понять, как может произойти сбой (при обучении GAN), давайте сначала обучим стабильную сеть GAN. Мы будем использовать набор данных MNIST, нашей целью будет создание искусственных рукописных цифр из случайного шума с использованием сети генератора.
Генератор примет на вход случайный шум, а на выходе будут фальшивые рукописные цифры размером 28×28. Дискриминатор будет принимать входные изображения 28 × 28 как от генератора, так и от наземной правды, и попытается правильно их классифицировать.
Я взял скорость обучения 0,0002 для оптимизатора Адама и 0,5 в качестве импульса для оптимизатора Адама.
Давайте посмотрим на код нашей стабильной сети GAN. Во-первых, давайте сделаем необходимый импорт.
импортная горелка импортировать torch.nn как nn импортировать torchvision.transforms как преобразования импортировать torch.
 optim как optim
импортировать torchvision.datasets как наборы данных
импортировать numpy как np
из torchvision.utils импортировать make_grid
из torch.utils.data импортировать DataLoader
из tqdm импортировать tqdm
импортировать neptune.new как neptune
из файла импорта neptune.new.types
optim как optim
импортировать torchvision.datasets как наборы данных
импортировать numpy как np
из torchvision.utils импортировать make_grid
из torch.utils.data импортировать DataLoader
из tqdm импортировать tqdm
импортировать neptune.new как neptune
из файла импорта neptune.new.types Обратите внимание, что в этом упражнении мы будем использовать PyTorch для обучения нашей модели и панель инструментов neptune.ai для отслеживания экспериментов. Вот ссылка на все мои эксперименты. Я запускал сценарии в colab, и Neptune упростил отслеживание всех экспериментов.
Правильное отслеживание эксперимента в этом случае действительно важно, потому что графики потерь и промежуточные изображения могут очень помочь определить, есть ли режим отказа. В качестве альтернативы вы можете использовать matplotlib, священный, TensorBoard и т. д., в зависимости от вашего варианта использования и комфорта.
Сначала мы инициализируем запуск Neptune. Вы можете получить путь к проекту и токен API после создания проекта на панели инструментов Neptune.
запуск = neptune.init( проект="имя проекта", api_token="Ваш токен API", )
Мы сохраняем размер партии 1024 и будем работать в течение 100 эпох. Скрытое измерение инициализируется для генерации случайных данных для ввода генератора. И размер выборки будет использоваться для вывода 64 изображений в каждую эпоху, чтобы мы могли визуализировать качество изображений после каждой эпохи. k — количество шагов, для которых мы собираемся запускать дискриминатор.
размер_пакета = 1024
эпохи = 100
размер_образца = 64
скрытый_дим = 128
к = 1
устройство = torch.device('cuda', если torch.cuda.is_available() иначе 'процессор')
преобразование = преобразование.Составить([
преобразовывает.ToTensor(),
преобразовывает. Нормализовать ((0,5,), (0,5,)),
])
Теперь мы загружаем данные MNIST и создаем объект Dataloader.
train_data = наборы данных.MNIST( корень='../ввод/данные', поезд = правда, скачать = Верно, трансформировать = трансформировать ) train_loader = DataLoader (train_data, batch_size=batch_size, shuffle=True)
Наконец, мы определяем некоторые гиперпараметры для обучения и передаем их на панель мониторинга Neptune с помощью объекта запуска.
параметров = {"learning_rate": 0,0002,
"оптимизатор": "Адам",
"оптимизатор_бетас": (0,5, 0,999),
"латентный_дим": латентный_дим}
run["parameters"] = params Здесь мы определяем сети генератора и дискриминатора.
Генераторная сеть
- Генераторная модель использует в качестве входных данных скрытое пространство, которое является случайным шумом.
- В первом слое мы меняем скрытое пространство (размерность 128) на функциональное пространство из 128 каналов и каждого канала высотой и шириной 7×7.
- Следуя двум слоям деконволюции, увеличьте высоту и ширину нашего пространства признаков.
- Затем следует слой свертки с активацией tanh для создания изображения с одним каналом и высотой и шириной 28×28.
Генератор класса (nn.Module):
def __init__(я, скрытое_пространство):
супер(Генератор, сам).__init__()
self.latent_space = скрытое_пространство
self.fcn = nn.Sequential(
nn. Linear(in_features=self.latent_space, out_features=128*7*7),
nn.LeakyReLU(0.2),
)
self.deconv = nn.Sequential(
nn.ConvTranspose2d (in_channels = 128, out_channels = 128, kernel_size = (4, 4), stride = (2, 2), padding = (1, 1)),
nn.LeakyReLU(0.2),
nn.ConvTranspose2d (in_channels = 128, out_channels = 128, kernel_size = (4, 4), stride = (2, 2), padding = (1, 1)),
nn.LeakyReLU(0.2),
nn.Conv2d (in_channels = 128, out_channels = 1, kernel_size = (3, 3), padding = (1, 1)),
nn.Tanh()
)
защита вперед (я, х):
х = self.fcn(x)
х = х.вид (-1, 128, 7, 7)
х = саморазвитие (х)
возврат х  Linear(in_features=self.latent_space, out_features=128*7*7),
nn.LeakyReLU(0.2),
)
self.deconv = nn.Sequential(
nn.ConvTranspose2d (in_channels = 128, out_channels = 128, kernel_size = (4, 4), stride = (2, 2), padding = (1, 1)),
nn.LeakyReLU(0.2),
nn.ConvTranspose2d (in_channels = 128, out_channels = 128, kernel_size = (4, 4), stride = (2, 2), padding = (1, 1)),
nn.LeakyReLU(0.2),
nn.Conv2d (in_channels = 128, out_channels = 1, kernel_size = (3, 3), padding = (1, 1)),
nn.Tanh()
)
защита вперед (я, х):
х = self.fcn(x)
х = х.вид (-1, 128, 7, 7)
х = саморазвитие (х)
возврат х
Linear(in_features=self.latent_space, out_features=128*7*7),
nn.LeakyReLU(0.2),
)
self.deconv = nn.Sequential(
nn.ConvTranspose2d (in_channels = 128, out_channels = 128, kernel_size = (4, 4), stride = (2, 2), padding = (1, 1)),
nn.LeakyReLU(0.2),
nn.ConvTranspose2d (in_channels = 128, out_channels = 128, kernel_size = (4, 4), stride = (2, 2), padding = (1, 1)),
nn.LeakyReLU(0.2),
nn.Conv2d (in_channels = 128, out_channels = 1, kernel_size = (3, 3), padding = (1, 1)),
nn.Tanh()
)
защита вперед (я, х):
х = self.fcn(x)
х = х.вид (-1, 128, 7, 7)
х = саморазвитие (х)
возврат х См. также
➡️ 6 архитектур GAN, которые вы действительно должны знать
Сеть дискриминатора
- Наша сеть дискриминатора состоит из двух сверточных слоев для генерации признаков из изображения, поступающего от генератора, и реальных изображений.
- За ним следует слой классификатора, который классифицирует, является ли изображение предсказанным дискриминатором реальным или поддельным.

Дискриминатор класса (nn.Module):
защита __init__(сам):
супер(Дискриминатор, я).__init__()
self.conv = nn.Sequential(
nn.Conv2d (in_channels = 1, out_channels = 64, kernel_size = (4, 4), шаг = (2, 2), заполнение = (1, 1)),
nn.LeakyReLU(0.2),
nn.Conv2d (in_channels = 64, out_channels = 64, kernel_size = (4, 4), шаг = (2, 2), заполнение = (1, 1)),
nn.LeakyReLU(0.2)
)
self.classifier = nn.Sequential(
nn.Linear(in_features=3136, out_features=1),
nn.Сигмоид()
)
защита вперед (я, х):
х = самоутверждение (х)
х = х.вид (х.размер (0), -1)
х = самоклассификатор (х)
возврат х Теперь мы инициализируем сеть генератора и дискриминатора, а также оптимизаторы и функцию потерь.
И у нас есть несколько вспомогательных функций для создания меток для поддельных и реальных изображений (где size — это размер пакета) и функция create_noise для ввода генератора.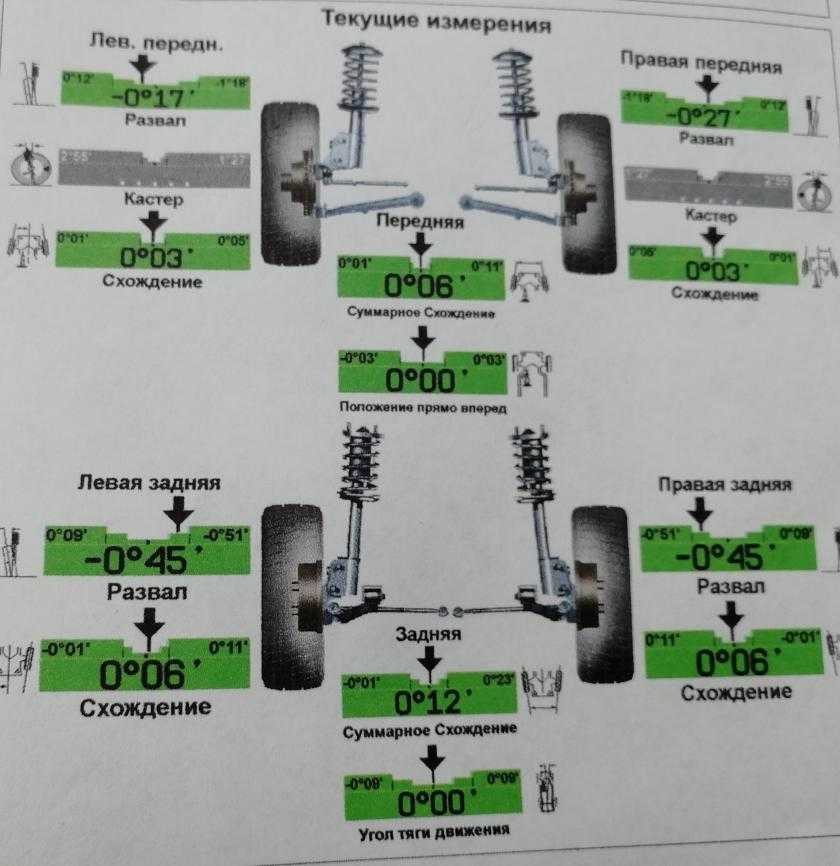
генератор = Генератор (latent_dim).to (устройство) дискриминатор = дискриминатор().к(устройство) optim_g = optim.Adam (параметры генератора (), lr = 0,0002, бета = (0,5, 0,999)) optim_d = optim.Adam (дискриминатор. параметры (), lr = 0,0002, бета = (0,5, 0,999)) критерий = nn.BCELoss() def label_real (размер): labels = torch.ones(размер, 1) вернуть labels.to(устройство) определение label_fake (размер): labels = torch.zeros(размер, 1) вернуть labels.to(устройство) def create_noise (sample_size, hidden_dim): return torch.randn(sample_size, hidden_dim).to(device)
Функция обучения генератора
Теперь мы обучим генератор:
- Генератор принимает случайный шум и выдает поддельные изображения.
- Эти поддельные изображения затем отправляются в дискриминатор, и теперь мы минимизируем потери между реальной меткой и предсказанием дискриминатора поддельного изображения.
- С помощью этой функции мы будем наблюдать потери генератора.

def train_generator (оптимизатор, data_fake): b_size = data_fake.size (0) реальная_метка = реальная_метка(b_size) оптимизатор.zero_grad() вывод = дискриминатор (data_fake) потеря = критерий (выход, реальная_метка) потеря.назад() оптимизатор.шаг() обратная потеря
Функция обучения дискриминатора
Мы создаем функцию train_discriminator:
- Эта сеть, как мы знаем, получает входные данные от наземной истины (т.е. реальных изображений) и генераторной сети (т.е. поддельных изображений) во время обучения.
- Одно за другим мы передаем поддельное и реальное изображение, вычисляем потери и обратное распространение. Мы будем наблюдать две потери дискриминатора; потери на реальных изображениях (loss_real) и потери на поддельных изображениях (loss_fake).
def train_distributor (оптимизатор, data_real, data_fake): b_size = data_real.size (0) реальная_метка = реальная_метка(b_size) поддельная_метка = метка_поддельная (b_size) оптимизатор.
 zero_grad()
output_real = дискриминатор (data_real)
loss_real = критерий (output_real, real_label)
output_fake = дискриминатор (data_fake)
loss_fake = критерий (output_fake, fake_label)
loss_real.backward()
loss_fake.backward()
оптимизатор.шаг()
возврат loss_real, loss_fake
zero_grad()
output_real = дискриминатор (data_real)
loss_real = критерий (output_real, real_label)
output_fake = дискриминатор (data_fake)
loss_fake = критерий (output_fake, fake_label)
loss_real.backward()
loss_fake.backward()
оптимизатор.шаг()
возврат loss_real, loss_fake Обучение модели GAN
Теперь, когда у нас есть все функции, давайте обучим нашу модель и посмотрим на наблюдения, чтобы определить, стабильно ли обучение или нет.
- Шум в первой строке будет использоваться для вывода промежуточных изображений после каждой эпохи. Мы сохраняем шум одинаковым, чтобы мы могли сравнивать изображения в разные эпохи.
- Теперь для каждой эпохи мы обучаем дискриминатор k раз (один раз в данном случае, поскольку k=1), за каждый раз обучается генератор.
- Все потери регистрируются и отправляются на панель управления Neptune для построения графика. Нам не нужно добавлять их в список, используя панель инструментов Neptune, мы можем строить графики потерь на лету. Он также будет записывать потери на каждом этапе в файле .csv.
- Я сохранил сгенерированные изображения после каждой эпохи в метаданных Neptune, используя функцию [dot]upload.
 Он также будет записывать потери на каждом этапе в файле .csv.
Он также будет записывать потери на каждом этапе в файле .csv. шум = создать_шум (размер выборки, скрытый_тусклый)
генератор.поезд()
дискриминатор.train()
для эпохи в диапазоне (эпохи):
потеря_г = 0,0
loss_d_real = 0,0
loss_d_fake = 0,0
# подготовка
для bi данные в tqdm(enumerate(train_loader), total=int(len(train_data)/train_loader.batch_size)):
изображение, _ = данные
изображение = изображение.на(устройство)
b_size = длина (изображение)
для шага в диапазоне (k):
data_fake = генератор (создать_шум (b_size, скрытый_дим)). отсоединить ()
data_real = изображение
loss_d_fake_real = train_distributor (optim_d, data_real, data_fake)
loss_d_real += loss_d_fake_real[0]
loss_d_fake += loss_d_fake_real[1]
data_fake = генератор (создать_шум (b_size, скрытый_дим))
loss_g += train_generator(optim_g, data_fake)
# вывод и наблюдения
сгенерированный_img = генератор (шум). процессор (). отсоединить ()
сгенерированный_img = make_grid (сгенерированный_img)
сгенерированный_img = np.moveaxis (сгенерированный_img.numpy (), 0, -1)
run[f'generated_img/{эпоха}'].upload(File.as_image(generated_img))
epoch_loss_g = loss_g / би
epoch_loss_d_real = loss_d_real/bi
epoch_loss_d_fake = loss_d_fake/би
run["train/loss_generator"].log(epoch_loss_g)
run["поезд/убыток_дискриминатор_реальный"].log(epoch_loss_d_real)
run["поезд/потеря_дискриминатора_фальшивка"].log(epoch_loss_d_fake)
print(f"Эпоха {эпоха} из {эпох}")
print(f"Потеря генератора: {epoch_loss_g:.8f}, Ложная потеря дискриминатора: {epoch_loss_d_fake:.8f}, Реальная потеря дискриминатора: {epoch_loss_d_real:.8f}")  процессор (). отсоединить ()
сгенерированный_img = make_grid (сгенерированный_img)
сгенерированный_img = np.moveaxis (сгенерированный_img.numpy (), 0, -1)
run[f'generated_img/{эпоха}'].upload(File.as_image(generated_img))
epoch_loss_g = loss_g / би
epoch_loss_d_real = loss_d_real/bi
epoch_loss_d_fake = loss_d_fake/би
run["train/loss_generator"].log(epoch_loss_g)
run["поезд/убыток_дискриминатор_реальный"].log(epoch_loss_d_real)
run["поезд/потеря_дискриминатора_фальшивка"].log(epoch_loss_d_fake)
print(f"Эпоха {эпоха} из {эпох}")
print(f"Потеря генератора: {epoch_loss_g:.8f}, Ложная потеря дискриминатора: {epoch_loss_d_fake:.8f}, Реальная потеря дискриминатора: {epoch_loss_d_real:.8f}")
процессор (). отсоединить ()
сгенерированный_img = make_grid (сгенерированный_img)
сгенерированный_img = np.moveaxis (сгенерированный_img.numpy (), 0, -1)
run[f'generated_img/{эпоха}'].upload(File.as_image(generated_img))
epoch_loss_g = loss_g / би
epoch_loss_d_real = loss_d_real/bi
epoch_loss_d_fake = loss_d_fake/би
run["train/loss_generator"].log(epoch_loss_g)
run["поезд/убыток_дискриминатор_реальный"].log(epoch_loss_d_real)
run["поезд/потеря_дискриминатора_фальшивка"].log(epoch_loss_d_fake)
print(f"Эпоха {эпоха} из {эпох}")
print(f"Потеря генератора: {epoch_loss_g:.8f}, Ложная потеря дискриминатора: {epoch_loss_d_fake:.8f}, Реальная потеря дискриминатора: {epoch_loss_d_real:.8f}") Посмотрим на промежуточные изображения.
Эпоха 10
Рис. 1 – Цифры, сгенерированные стабильной GAN на 10-й эпохе | Источник: АвторЭто 64 цифры, сгенерированные в эпоху 10.
Эпоха 100
Рис. Источник: Автор Они созданы с использованием того же шума в эпоху 100. Они выглядят намного лучше, чем изображения в эпоху 10, здесь мы действительно можем идентифицировать разные цифры. Мы можем обучаться еще большему количеству эпох или настраивать гиперпараметры для лучшего качества изображений.
Они выглядят намного лучше, чем изображения в эпоху 10, здесь мы действительно можем идентифицировать разные цифры. Мы можем обучаться еще большему количеству эпох или настраивать гиперпараметры для лучшего качества изображений.
Графики убытков
Вы можете легко перейти в «Добавить новую панель мониторинга» на панели мониторинга Neptune и объединить различные графики потерь в один.
Рис. 3 – График потерь, три линии показывают потери для генератора, поддельные изображения на дискриминаторе и реальные изображения на дискриминаторе | Источник На рис. 3 вы можете наблюдать стабилизацию потерь после эпохи 40. Потери дискриминатора для реального и поддельного изображений остаются около 0,6, тогда как для генератора они составляют около 0,8. Приведенный выше график является ожидаемым графиком для стабильной тренировки. Мы можем рассматривать это как базовый уровень и экспериментировать с изменением k (шаги обучения для дискриминатора), увеличением количества эпох и т.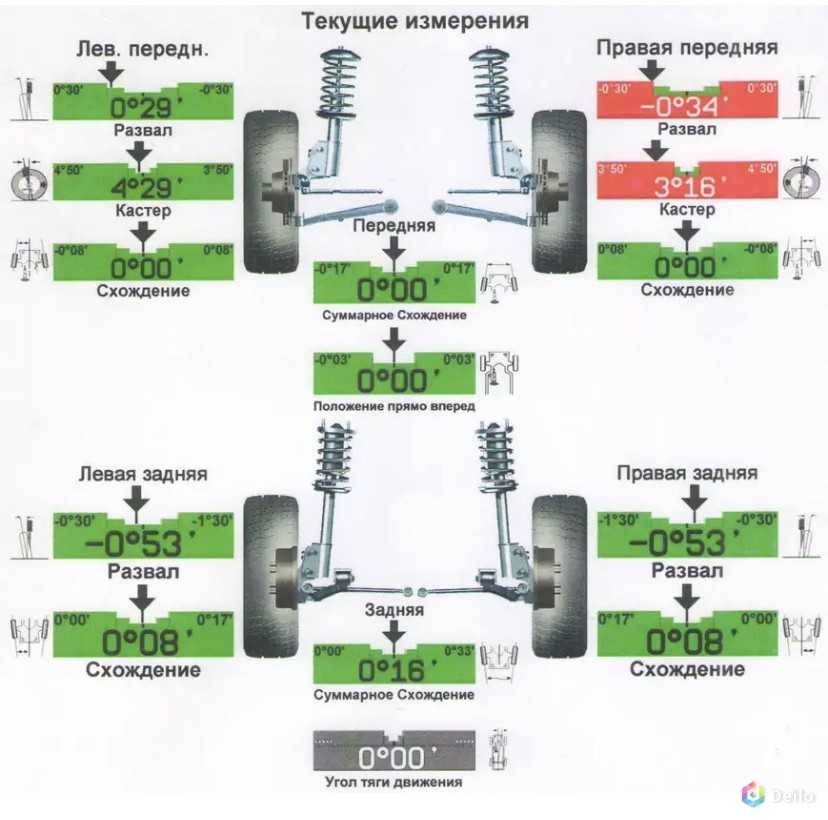 д.
д.
Теперь, когда мы построили стабильную модель GAN, давайте посмотрим на режимы отказа.
Связанные
➡️ Понимание функций потери GAN
Режимы отказа GAN
В последние годы мы наблюдаем быстрый рост приложений GAN, будь то увеличение разрешения изображений, условная генерация или генерация реальных как синтетические данные.
Неудача в обучении является серьезной проблемой для таких приложений.
Как определить режимы отказа GAN? Как мы узнаем, есть ли режим отказа:
- В идеале генератор должен выдавать разнообразные данные. Если он производит один вид или аналогичный набор выходных данных, это Mode Collapse .
- Когда создается набор визуально неверных данных, это может быть случаем Ошибка конвергенции .
Что вызывает сбой режима в GAN? Причины режимов отказа:
- Невозможность найти конвергенцию для сетей.
- Генератор может найти определенный тип данных, который может легко обмануть дискриминатор. Он будет снова и снова генерировать одни и те же данные, предполагая, что цель достигнута. Вся система может переоптимизировать этот единственный тип вывода.
 Он будет снова и снова генерировать одни и те же данные, предполагая, что цель достигнута. Вся система может переоптимизировать этот единственный тип вывода.
Он будет снова и снова генерировать одни и те же данные, предполагая, что цель достигнута. Вся система может переоптимизировать этот единственный тип вывода.Проблема с определением сбоя режима и других режимов отказа заключается в том, что мы не можем полагаться на качественный анализ (например, на просмотр данных вручную). Этот метод может дать сбой, если имеется огромное количество данных или если проблема действительно сложна (мы не всегда будем генерировать цифры).
Оценка режимов отказа
В этом разделе мы попытаемся понять, как определить, имеет ли место сбой режима или сбой конвергенции. Мы увидим три метода оценки. Один из них мы уже обсуждали в предыдущем разделе.
Глядя на промежуточные изображения
Давайте посмотрим несколько примеров, где по промежуточным изображениям можно оценить режим коллапса и конвергенции. На рис. 4 мы видим изображения действительно плохого качества, а на рис. 5 мы видим тот же набор сгенерированных изображений.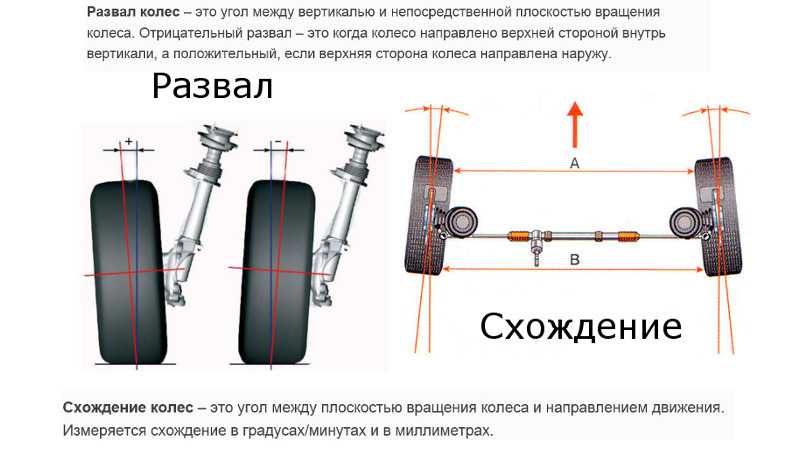
Хотя на рис. 4 показан пример сбоя сходимости, на рис. 5 показан сбой режима. Вы можете получить представление о том, как работает ваша модель, просмотрев изображения вручную. Но когда сложность проблемы высока или данные для обучения слишком велики, вы не сможете идентифицировать коллапс режима.
Давайте рассмотрим несколько лучших методов.
По графикам потерь
Мы можем многое узнать о том, что происходит, посмотрев на графики потерь. Например, на рис. 3 вы можете заметить, что потери насыщаются после определенного момента, демонстрируя ожидаемое поведение. Теперь давайте посмотрим на этот график потерь на рис. 6, где я уменьшил скрытое измерение, поэтому поведение неустойчиво.
6, где я уменьшил скрытое измерение, поэтому поведение неустойчиво.
Как видно на рис. 6, потери генератора колеблются между 1 и 1,2. Хотя потери дискриминатора для поддельных и реальных изображений также колеблются около 0,6, потери несколько больше, чем мы заметили в стабильной версии.
Я бы посоветовал, даже если график имеет высокую дисперсию, это нормально. Вы можете увеличить количество эпох и подождать еще некоторое время, пока оно не станет стабильным, и, самое главное, продолжать проверять сгенерированные промежуточные изображения.
Если график потерь падает до нуля в начальные эпохи как для генератора, так и для дискриминатора, то это тоже проблема. Это означает, что генератор нашел набор поддельных изображений, которые действительно легко идентифицировать дискриминатору.
Количество статистически различных интервалов (показатель NDB)
В отличие от двух вышеупомянутых качественных методов, оценка NDB является количественным методом. Таким образом, вместо того, чтобы просматривать изображения и графики потерь и что-то упускать или делать неправильную интерпретацию, оценка NDB может определить, есть ли сбой режима.
Таким образом, вместо того, чтобы просматривать изображения и графики потерь и что-то упускать или делать неправильную интерпретацию, оценка NDB может определить, есть ли сбой режима.
Давайте разберемся, как работает оценка NDB:
- У нас есть два набора, обучающий набор (на котором обучается модель) и тестовый набор (фальшивые изображения, сгенерированные генератором на случайном шуме после обучения).
- Теперь разделите обучающую выборку на K кластеров, используя кластеризацию K-средних. Это будут наши K разных бункеров.
- Теперь распределите тестовые данные по этим K интервалам на основе евклидова расстояния между точками тестовых данных и центроидами K кластеров.
- Теперь проведите тест с двумя выборками между обучающей и тестовой выборками для каждого бина и рассчитайте Z-показатель. Если Z-оценка меньше порогового значения (в статье используется 0,05), пометьте ячейку как статистически отличающуюся.
- Подсчитайте количество статистически различных бинов и разделите их на K.
- Полученное значение будет находиться в диапазоне от 0 до 1.

Большое количество статистически различных бинов означает, что значение ближе к 1, что означает коллапс высокой моды, что означает плохой модель. Тем не менее, оценка NDB, приближающаяся к 0, означает меньшее коллапс режима или его отсутствие.
Метод оценки NDB взят из статьи О GAN и GMM.
Рис. 7 — (a) Вверху слева — изображение из набора обучающих данных (b) Внизу слева — изображение из набора тестовых данных и показано перекрытие (c) Гистограмма, показывающая бины для обучающего и тестового набора | ИсточникОчень хорошо реализованный код для расчета NDB можно найти в этом блокноте совместной работы Кевина Шена.
Устранение режимов отказа
Теперь, когда у нас есть понимание того, как выявлять проблемы при обучении GAN, мы рассмотрим некоторые решения и эмпирические правила для их решения. Некоторые из них будут базовыми настройками гиперпараметров. Мы обсудим некоторые алгоритмы, если вы хотите сделать все возможное, чтобы стабилизировать свои GAN.
Функции стоимости
Есть документы, в которых говорится, что ни одна функция потерь не имеет превосходства. Я бы посоветовал вам начать с более простых функций потерь, таких как мы используем бинарную кросс-энтропию, и подняться оттуда.
Теперь нет необходимости использовать определенные функции потерь с определенными архитектурами GAN. Но для написания этих статей было проведено много исследований, многие из которых все еще активны. Таким образом, было бы хорошей практикой использовать эти функции потерь на рис. 8, которые могут помочь вам предотвратить как коллапс моды, так и конвергенцию.
Рис. 8 – Архитектура GAN и соответствующие функции потерь, использованные в статьях | Источник Поэкспериментируйте с различными функциями потерь и обратите внимание, что ваша функция потерь может дать сбой из-за неправильной настройки гиперпараметров, например слишком агрессивного оптимизатора или большой скорости обучения. Мы поговорим об этих проблемах позже.
Скрытое пространство
Скрытое пространство — это место, откуда берется входной сигнал для генератора (случайный шум). Теперь, если вы ограничите скрытое пространство, оно будет производить больше выходных данных того же типа, что видно из рис. 9. Вы также можете посмотреть на соответствующий график потерь на рис. 6.
Рис. пространство 2 | Источник: АвторНа рис. 9 вы видите столько одинаковых восьмерок и семерок? Отсюда и коллапс режима.
Рис. 10. Здесь я указал скрытое пространство равным 1, пробежал на 200 эпох.Мы можем видеть постоянно увеличивающиеся потери генератора и колебания во всех потерях | Источник Рис. 11 – Подучасток, соответствующий рис. 10, где скрытое пространство равно 1.
Эти цифры генерируются на 200-й эпохе | Источник: Автор
Обратите внимание, что при обучении сети GAN очень важно предоставить достаточное количество скрытого пространства, чтобы генератор мог создавать различные функции.
Скорость обучения
Одной из наиболее распространенных проблем, с которыми я столкнулся при обучении GAN, является высокая скорость обучения. Это приводит либо к коллапсу мод, либо к неконвергенции. Очень важно, чтобы вы поддерживали скорость обучения на низком уровне, всего 0,0002 или даже ниже.
Рис. 12 – Значения потерь при скорости обучения 0,2 | Источник Рис. 13 — Сгенерированные изображения на 100-й эпохе со скоростью обучения 0,2 | Источник: АвторИз графика потерь на рис. 12 ясно видно, что дискриминатор идентифицирует все изображения как реальные. Вот почему потери для поддельных изображений высоки, а для реальных изображений нет. Теперь генератор предполагает, что все созданные им изображения обманывают дискриминатор. Проблема здесь в том, что дискриминатор даже немного не обучается из-за такой высокой скорости обучения.
Чем выше размер пакета, тем выше может быть значение скорости обучения, но всегда старайтесь быть на более безопасной стороне.
Оптимизатор
Агрессивный модификатор — плохая новость для обучения GAN. Это приводит к невозможности найти равновесие между потерями генератора и потерями дискриминатора и, следовательно, сбоем сходимости.
Рис. 14 – График потерь со значениями по умолчанию для Adam Optimizer (бета 0,9 и 0,999) | ИсточникВ Adam Optimizer бета — это гиперпараметры, используемые для вычисления скользящего среднего значения градиента и его квадрата. Мы изначально (в стабильном обучении) использовали значение 0,5 для бета1. Меняем на 0.9(значение по умолчанию) увеличивает агрессивность оптимизатора.
На рис. 14 дискриминатор работает хорошо. Поскольку потери генератора увеличиваются, мы можем сказать, что он создает такие плохие изображения, что дискриминатору очень легко классифицировать их как поддельные. График потерь не достигает равновесия.
Сопоставление признаков
Сопоставление признаков предлагает новую целевую функцию, в которой мы не используем напрямую выходные данные дискриминатора. Генератор обучен таким образом, что ожидается, что выходные данные генератора будут соответствовать значениям реальных изображений на промежуточных признаках дискриминатора.
Генератор обучен таким образом, что ожидается, что выходные данные генератора будут соответствовать значениям реальных изображений на промежуточных признаках дискриминатора.
Для реального изображения и фальшивого изображения векторы признаков (f(x) на рис. 15) вычисляются на промежуточном слое в мини-пакетах, и измеряется расстояние L2 по средним значениям этих векторов признаков.
Имеет смысл сопоставлять сгенерированные данные со статистикой реальных данных. В случае, если оптимизатор становится слишком жадным в поисках наилучшей генерации данных и никогда не достигает сходимости, сопоставление признаков может быть полезным.
Историческое усреднение
Мы сохраняем скользящее среднее значение параметров (θ) предыдущего t числа моделей. Теперь мы штрафуем модель, добавляя стоимость L2 к функции стоимости, используя предыдущие параметры.
Рис.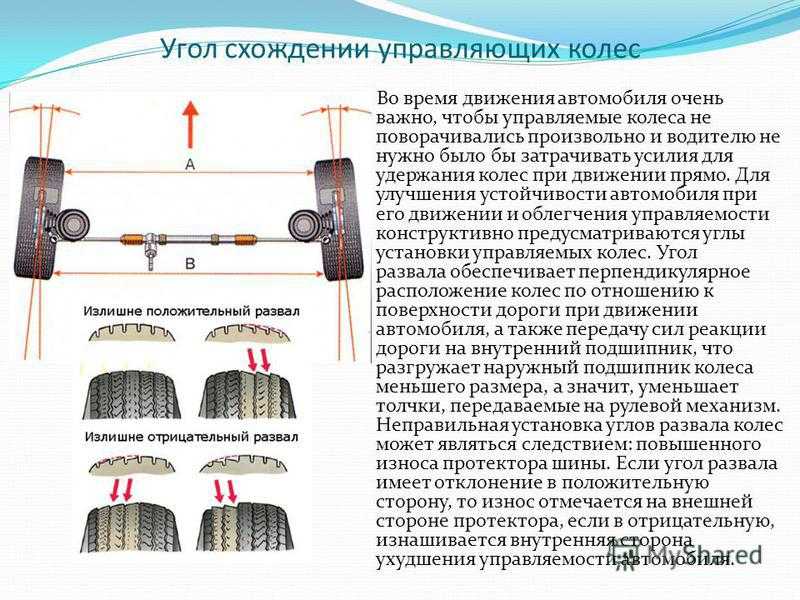 16 – Стоимость L2 | Источник
16 – Стоимость L2 | Источник Здесь θ[i] — значение параметра на i -м -м прогоне.
При работе с невыпуклыми целевыми функциями историческое усреднение может помочь сходимости модели.
Заключение
- Теперь мы понимаем важность отслеживания экспериментов при обучении GAN.
- Важно понимать графики потерь и внимательно наблюдать за генерируемыми промежуточными данными.
- Гиперпараметры, такие как скорость обучения, параметры оптимизатора, скрытое пространство и т. д., могут испортить вашу модель, если они не настроены должным образом.
- С увеличением количества моделей GAN за последние несколько лет все больше и больше исследований проводится в области стабилизации обучения GAN. Есть гораздо больше методов, полезных для конкретных случаев использования.
Читать далее
- https://arxiv.org/pdf/1606.03498v1.pdf
- https://towardsdatascience.com/10-lessons-i-learned-training-generative-adversarial-networks-gans-for-a-year-c9071159628
- https://towardsdatascience. com/gan- способы улучшения ган-производительности-acf37f9f59b
- https://arxiv.org/pdf/1805.12462.pdf
 com/gan- способы улучшения ган-производительности-acf37f9f59b
com/gan- способы улучшения ган-производительности-acf37f9f59bЧИТАТЬ СЛЕДУЮЩИЙ
Полное руководство по оценке и выбору моделей в машинном обучении 9 9002 10 минут чтения | Автор Самадрита Гош | Обновлено 16 июля 2021 г.
На высоком уровне машинное обучение представляет собой союз статистики и вычислений. Суть машинного обучения вращается вокруг концепции алгоритмов или моделей, которые на самом деле являются статистическими оценками на стероидах.
Однако любая модель имеет ряд ограничений в зависимости от распределения данных. Ни один из них не может быть полностью точным, так как это просто оценки (даже если на стероидах) . Эти ограничения широко известны под названием 9.0142 смещение
и дисперсия . Модель с высоким смещением будет чрезмерно упрощать, не уделяя особого внимания точкам обучения (например, в линейной регрессии, независимо от распределения данных, модель всегда будет предполагать линейную зависимость).
Модель с высокой дисперсией ограничится обучающими данными, не обобщая тестовые точки, которых она не видела раньше (например, случайный лес с max_depth = None).
Проблема возникает, когда ограничения незначительны, например, когда нам приходится выбирать между алгоритмом случайного леса и алгоритмом повышения градиента или между двумя вариантами одного и того же алгоритма дерева решений. Оба будут иметь тенденцию к высокой дисперсии и низкому смещению.
Здесь в игру вступают выбор и оценка модели!
В этой статье мы поговорим о:
- Что такое выбор модели и оценка модели?
- Эффективные методы выбора модели (повторная выборка и вероятностные подходы)
- Популярные методы оценки модели
- Важные недостатки модели машинного обучения
Продолжить чтение ->
Мониторинг прогресса обучения GAN и выявление распространенных режимов отказа — MATLAB & Simulink
Основное содержание
Мониторинг прогресса обучения GAN и выявление общих режимов отказа
Обучение GAN может быть сложной задачей.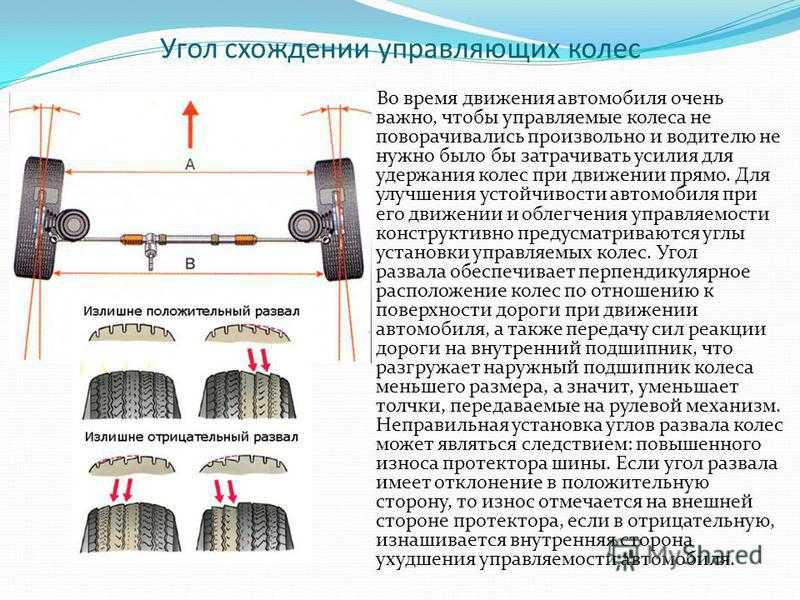 Это связано с тем, что генератор и
дискриминаторные сети конкурируют друг с другом во время обучения. На самом деле, если один
сеть обучается слишком быстро, тогда другая сеть может не обучиться. Это часто может привести
в сети невозможно сойтись. Для диагностики проблем и мониторинга по шкале от 0
до 1, насколько хорошо генератор и дискриминатор достигают своих целей, которые вы можете построить
их баллы. Для примера, показывающего, как обучить GAN и построить генератор и
баллы дискриминатора, см. Обучение генеративно-состязательной сети (GAN). 9Real содержит выходные вероятности дискриминатора для реальных изображений и
числа реальных и сгенерированных изображений, переданных дискриминатору, равны.
Это связано с тем, что генератор и
дискриминаторные сети конкурируют друг с другом во время обучения. На самом деле, если один
сеть обучается слишком быстро, тогда другая сеть может не обучиться. Это часто может привести
в сети невозможно сойтись. Для диагностики проблем и мониторинга по шкале от 0
до 1, насколько хорошо генератор и дискриминатор достигают своих целей, которые вы можете построить
их баллы. Для примера, показывающего, как обучить GAN и построить генератор и
баллы дискриминатора, см. Обучение генеративно-состязательной сети (GAN). 9Real содержит выходные вероятности дискриминатора для реальных изображений и
числа реальных и сгенерированных изображений, переданных дискриминатору, равны.
В идеальном случае обе оценки должны быть равны 0,5. Это потому, что дискриминатор не может сказать
разница между реальными и поддельными изображениями. Однако на практике этот сценарий не
единственный случай, когда вы можете добиться успешной ГАН.
Для наблюдения за ходом обучения вы можете визуально просматривать изображения с течением времени и проверять если они улучшаются. Если изображения не улучшаются, вы можете использовать график оценки для помочь вам диагностировать некоторые проблемы. В некоторых случаях график счета может сказать вам, что нет продолжать тренировку, и вы должны остановиться, потому что возник режим отказа, который тренировка не может оправиться от. В следующих разделах рассказывается, что искать в партитуре. на графике и в сгенерированных изображениях для диагностики некоторых распространенных режимов отказа (сбой конвергенции и свертывание режима) и предлагает возможные действия, которые можно предпринять для улучшения подготовка.
Ошибка сходимости
Ошибка сходимости происходит, когда генератор и дискриминатор не достигают баланс во время тренировки.
Дискриминатор доминирует
Этот сценарий происходит, когда показатель генератора достигает нуля или почти нуля, а
оценка дискриминатора достигает единицы или близка к единице.
На этом графике показан пример дискриминатора, подавляющего генератор. Уведомление что оценка генератора приближается к нулю и не восстанавливается. В этом случае дискриминатор правильно классифицирует большинство изображений. В свою очередь, генератор не может производить любые изображения, которые обманывают дискриминатор и, таким образом, не в состоянии учиться.
Если оценка не восстанавливается после этих значений в течение многих итераций, то лучше прекратить обучение. Если это произойдет, попробуйте сбалансировать производительность генератор и дискриминатор по:
Нарушение работы дискриминатора путем случайного присвоения ложных меток реальным изображения (одностороннее переворачивание меток)
Ухудшение работы дискриминатора путем добавления выпадающих слоев
Улучшение способности генератора создавать больше функций путем увеличение количества фильтров в его сверточных слоях
Ухудшение работы дискриминатора за счет уменьшения количества фильтров
Пример, показывающий, как переворачивать метки реальных изображений, см. в разделе Обучение генеративно-состязательной сети (GAN).
в разделе Обучение генеративно-состязательной сети (GAN).
Генератор доминирует
Этот сценарий происходит, когда счет генератора достигает единицы или почти единицы.
На этом графике показан пример того, как генератор подавляет дискриминатор. Уведомление что оценка генератора идет к единице для многих итераций. В этом случае генератор учится обманывать дискриминатор почти всегда. Когда это происходит очень в начале процесса обучения генератор, скорее всего, выучит очень простой представление признаков, которое легко обманывает дискриминатор. Это означает, что сгенерированные изображения могут быть очень плохими, несмотря на высокие баллы. Обратите внимание, что в этом Например, оценка дискриминатора не очень близка к нулю, потому что она все еще в состоянии правильно классифицировать некоторые реальные изображения.
Если оценка не восстанавливается после этих значений в течение многих итераций, то
лучше прекратить обучение. Если это произойдет, попробуйте сбалансировать производительность
генератор и дискриминатор по:
Если это произойдет, попробуйте сбалансировать производительность
генератор и дискриминатор по:
Улучшение способности дискриминатора изучать больше функций путем увеличение количества фильтров
Ухудшение работы генератора путем добавления отсеивающих слоев
Ухудшение работы генератора за счет уменьшения количества фильтров
Коллапс режима
Коллапс режима — это когда GAN создает небольшое количество изображений с большим количеством дубликатов. (режимы). Это происходит, когда генератор не может изучить расширенную функцию. представление, потому что оно учится связывать похожие результаты с несколькими разными входы. Чтобы проверить свертывание режима, проверьте сгенерированные изображения. если мало разнообразие в выводе и некоторые из них практически идентичны, то скорее всего режим крах.
На этом графике показан пример коллапса режима. Обратите внимание, что сгенерированные изображения строятся
содержит множество практически идентичных изображений, несмотря на то, что входные данные генератора были
разные и случайные.
Обратите внимание, что сгенерированные изображения строятся
содержит множество практически идентичных изображений, несмотря на то, что входные данные генератора были
разные и случайные.
Если вы наблюдаете подобное, то попробуйте увеличить способность генератора создавать более разнообразные результаты:
Увеличение размерности входных данных в генератор
Увеличение количества фильтров генератора, чтобы он мог генерировать широкий выбор функций
Нарушение работы дискриминатора путем случайного присвоения ложных меток реальным изображениям (одностороннее переключение меток)
Пример, показывающий, как переворачивать метки реальных изображений, см. в разделе Обучение генеративно-состязательной сети (GAN).
См. также
dlnetwork | вперед | предсказать | Дларрей | dlградиент | dlfeval | Адамобновление
Связанные темы
- Обучение генеративно-состязательной сети (GAN)
- Обучение условно генеративно-состязательной сети (CGAN)
- Определение пользовательских циклов обучения, функций потерь и сетей
- Обучение сети с использованием пользовательского цикла обучения Пользовательский Указать параметры обучения в Цикл обучения
- Список слоев глубокого обучения
- Советы и рекомендации по глубокому обучению
- Фон автоматического дифференцирования
Вы щелкнули ссылку, соответствующую этой команде MATLAB:
Запустите команду, введя ее в командном окне MATLAB.